너비 우선 탐색 (BFS, Breadth-First Search)
너비 우선 탐색 (BFS)
너비 우선 탐색(BFS, Breadth-First Search)은 시작 노드에서 가까운 노드부터 먼저 방문하고 점진적으로 깊이를 넓혀가며(Level-by-Level) 탐색하는 알고리즘입니다. 물가에 돌을 던졌을 때 퍼져나가는 동심원의 물결과 같은 형태로 동작하며, 주로 최단 경로(Shortest Path)를 찾을 때 가장 완벽한 해답을 제공합니다.
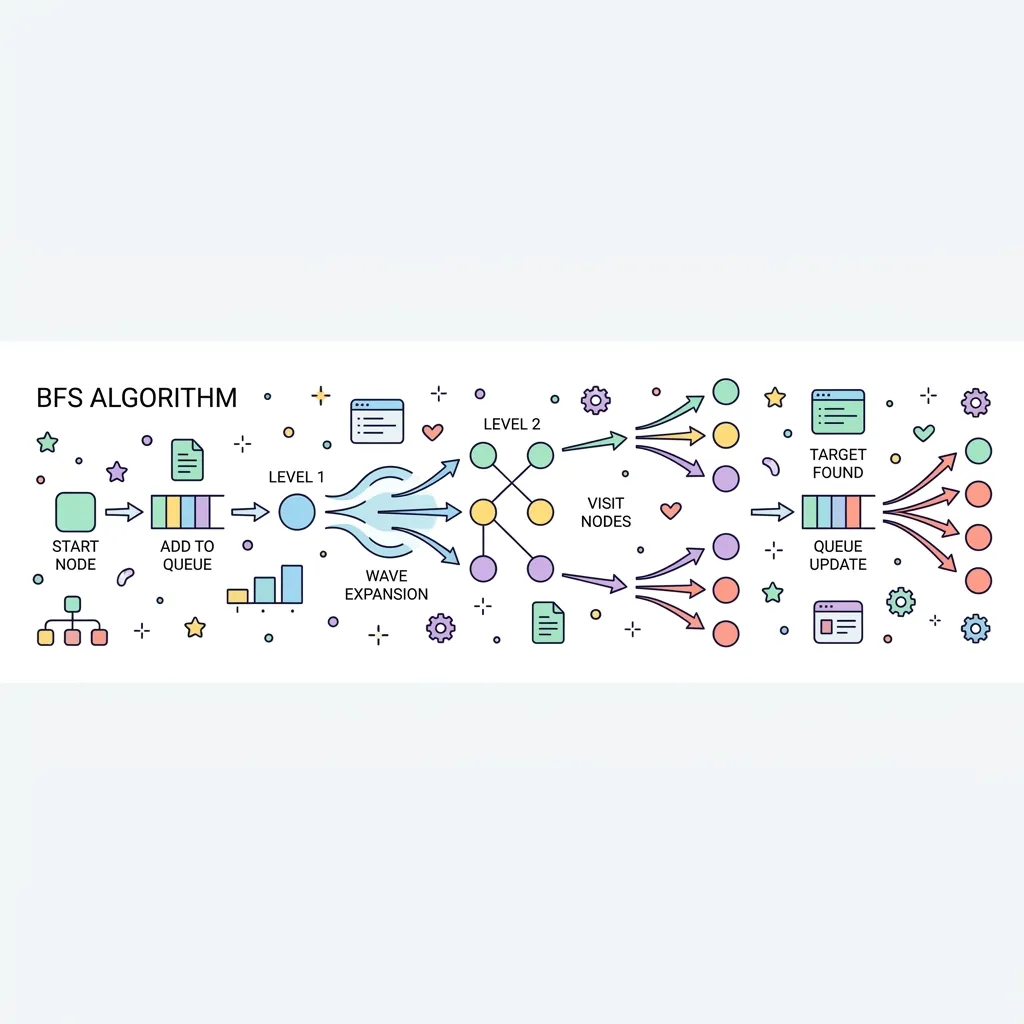
1. BFS의 작동 원리와 특징
BFS는 보통 먼저 들어온 데이터가 먼저 나가는 큐(Queue) 자료구조를 사용하여 구현합니다.
● 최단 경로 보장 : 한 단계(Level)씩 모든 가능성을 탐색하므로, 목표 노드를 발견하는 순간 그 경로가 최단 경로임을 100% 보장합니다.
● 큐(Queue) 활용 : 현재 노드에서 방문할 수 있는 인접 노드를 모두 큐에 밀어 넣고(Push), 순차적으로 꺼내며(Pop) 탐색합니다.
● 메모리 소모량 : 분기가 매우 많은 거대한 그래프의 경우 큐에 엄청난 수의 노드가 쌓이게 되어 DFS보다 메모리 사용량이 치명적으로 높아질 수 있습니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 시간 복잡도 (인접 리스트) | O(V + E) | V는 정점(Vertex), E는 간선(Edge)의 수입니다. DFS와 마찬가지로 모든 정점을 한 번씩 방문하고 간선을 스캔하므로 O(V + E)가 소요됩니다. |
| 시간 복잡도 (인접 행렬) | O(V²) | 그래프의 연결 형태를 확인하기 위해 V x V 행렬 전체를 순회해야 하므로 정점의 수가 매우 많고 간선이 적은 희소 그래프에서는 비효율적입니다. |
| 공간 복잡도 | O(V) | 최악의 경우(방사형 트리 등) 가장 넓은 레벨에 있는 모든 노드가 큐(Queue)에 한꺼번에 저장되므로, 메모리를 대량으로 차지할 수 있습니다. |
💡 실무 지식: 큐(Queue) 연산의 함정
자바스크립트 등 배열(Array)만 제공되는 언어에서 BFS를 구현할 때 queue.shift() (앞에서 빼기)를 사용하면 O(N) 시간 복잡도가 발생하여 전체 알고리즘 효율이 박살날 수 있습니다. 실무나 알고리즘 테스트에서는 반드시 앞뒤 삽입/삭제가 O(1)로 이뤄지는 연결 리스트 기반의 큐나 투 포인터(Two Pointer) 방식을 직접 구현하여 사용해야 합니다!