이진 탐색 (Binary Search)
이진 탐색 (Binary Search)
이진 탐색(Binary Search)은 반드시 정렬되어 있는 배열에서 특정한 값을 찾아내는 매우 빠르고 강력한 탐색 알고리즘입니다. 우리가 흔히 하는 '업다운(Up-Down) 게임'처럼 매번 탐색 범위를 절반씩 뚝뚝 잘라내가며 정답을 압축해 들어가는 방식입니다.
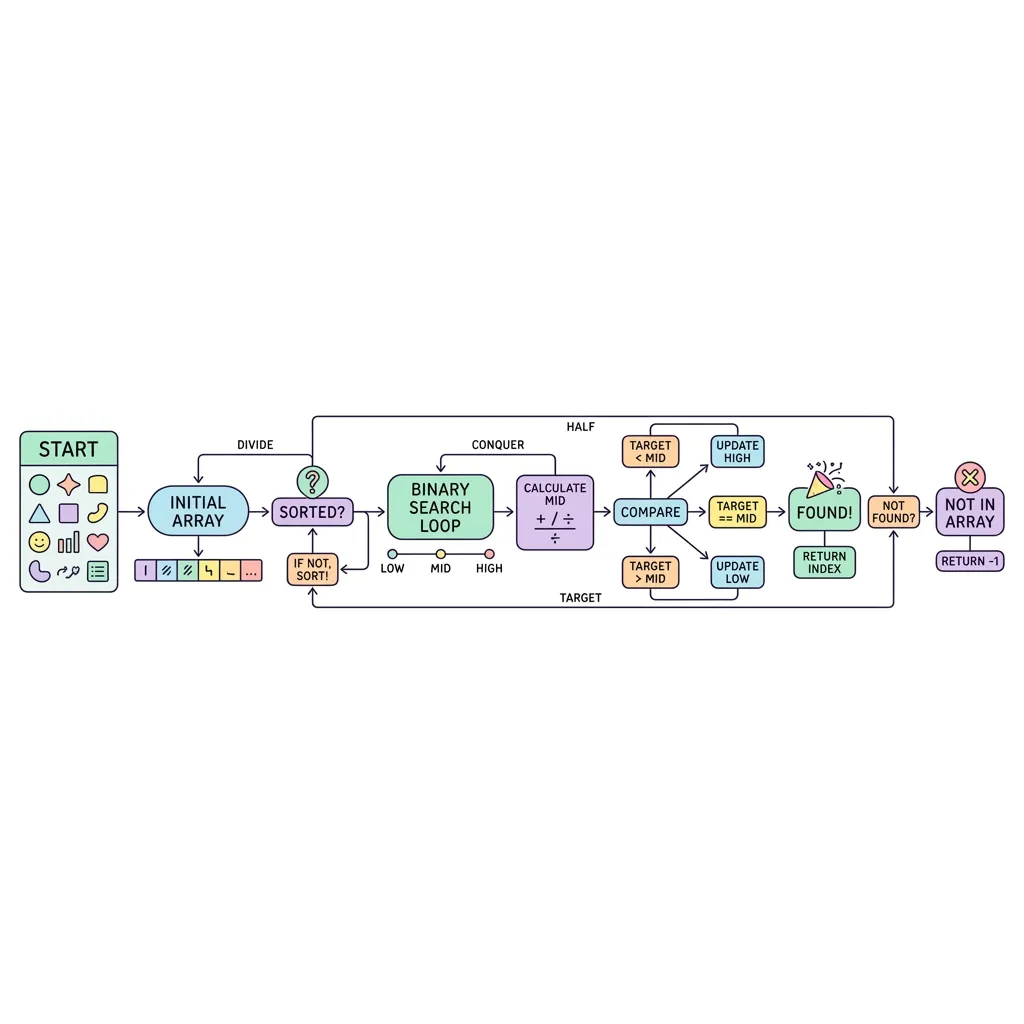
1. 이진 탐색의 작동 원리
이진 탐색은 분할 정복(Divide and Conquer)의 철학을 가장 잘 보여주는 탐색 기법입니다.
● 중앙값 비교 : 탐색 범위의 정중앙에 있는 값(Mid)을 선택해 찾고자 하는 타겟(Target)과 비교합니다.
● 범위 반갈죽(Half Discard) : 타겟이 중앙값보다 크다면 중앙값 기준 왼쪽 절반을 완전히 버리고 오른쪽만 탐색합니다(작다면 반대).
● 전제 조건 : 이 알고리즘이 성립하려면 데이터는 무조건 오름차순(또는 내림차순)으로 정렬되어 있어야만 합니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선 시간 복잡도 (Best) | O(1) | 처음 계산한 한가운데(Mid) 값이 우연히 우리가 찾으려던 타겟과 정확히 일치할 때입니다. |
| 평균/최악 시간 복잡도 | O(log N) | 순차 탐색 O(N)에 비해 기적적으로 빠릅니다. 예를 들어 43억 개의 데이터가 있어도 최대 32번만 비교하면 무조건 정답을 찾아냅니다. |
| 공간 복잡도 | O(1) | 반복문(while)으로 구현할 경우 Left, Right, Mid 포인터 변수만 있으면 되므로 별도 메모리를 차지하지 않습니다. |
💡 실무 지식: 오버플로우 방지 팁
자바(Java)나 C++ 같은 강타입 언어에서 mid = (left + right) / 2를 사용하면, 배열 크기가 엄청나게 클 경우 left + right 값이 int 자료형의 최댓값을 초과하여 오버플로우(Overflow) 에러가 발생할 수 있습니다. 실무에서는 이를 방지하기 위해 mid = left + (right - left) / 2 공식이나 비트 시프트 연산 (left + right) >>> 1을 사용하는 것이 정석입니다.