병합 정렬 (Merge Sort)
병합 정렬 (Merge Sort)
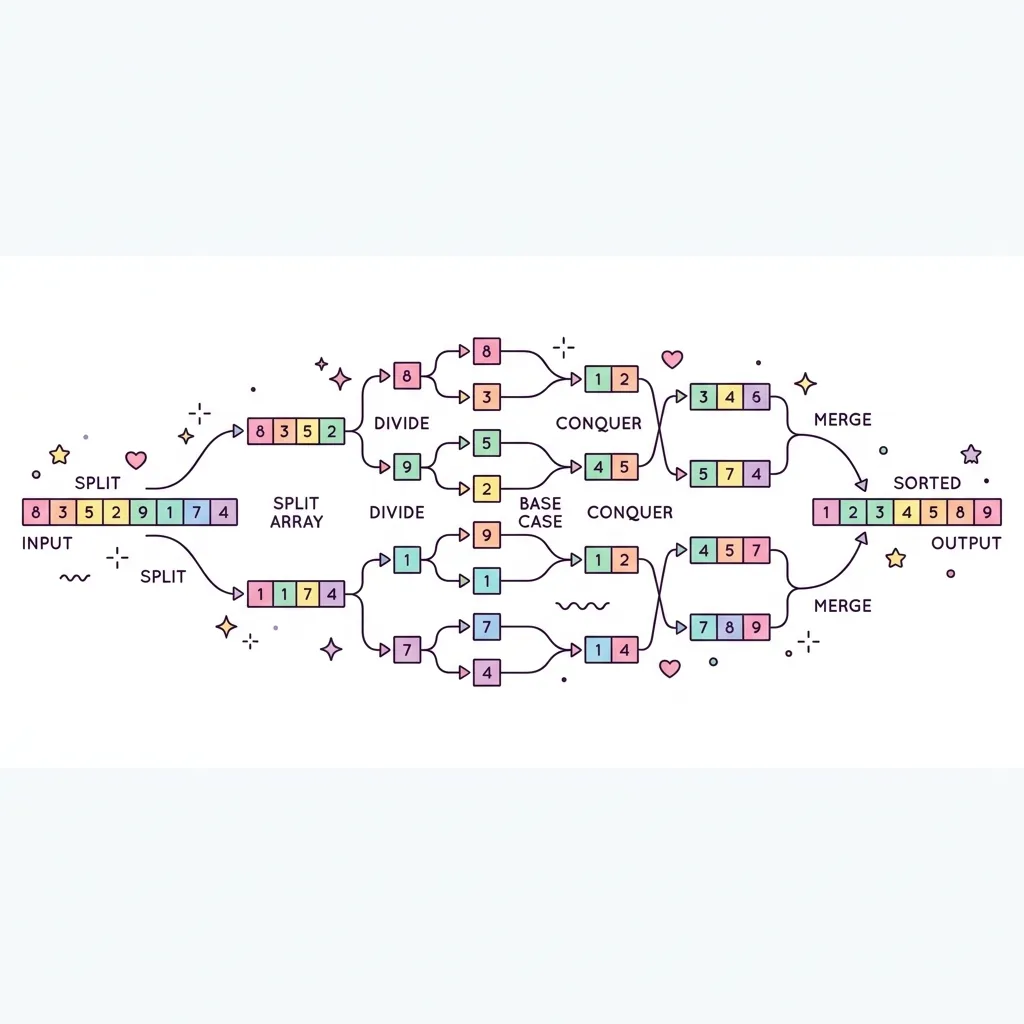
병합 정렬(Merge Sort)은 1945년 폰 노이만(John von Neumann)에 의해 개발된 알고리즘으로, 대표적인 분할 정복(Divide and Conquer) 패러다임을 사용하는 빠르고 안정적인 정렬 알고리즘입니다. 하나의 배열을 두 개의 균등한 크기로 끝까지 분할한 뒤, 부분 배열을 정렬하면서 다시 하나로 병합하는 과정을 거칩니다.
1. 분할 정복 (Divide and Conquer)이란?
병합 정렬은 다음 3단계의 논리적 흐름에 따라 작동합니다:
● Divide (분할) : 배열을 더 이상 나눌 수 없을 때까지(크기가 1이 될 때까지) 정확히 절반씩 나눕니다.
● Conquer (정복) : 나누어진 각 부분 배열을 정렬합니다. (요소가 1개라면 이미 정렬된 상태로 간주합니다.)
● Combine (결합) : 정렬된 부분 배열들을 두 개씩 묶어서 하나의 정렬된 배열로 병합(Merge) 합니다.
2. 병합 정렬의 주요 특징
[1] 안정 정렬 (Stable Sort)
배열 안에 값이 같은 두 요소가 있을 때, 정렬 후에도 그들의 상대적인 원래 순서가 변하지 않는 정렬입니다. 객체나 복합 데이터를 정렬할 때 기존의 정렬 기준이 유지되므로 매우 중요합니다.
[2] 일관된 성능 보장
데이터의 원래 분포 상태와 관계없이 언제나 배열을 반으로 나누기 때문에, 퀵 정렬(Quick Sort)의 최악의 경우(O(N²))와 같은 현상이 절대 발생하지 않고 어떤 상황에서도 O(N log N)의 성능을 보장합니다.
[3] 연결 리스트 (Linked List) 정렬에 탁월
순차적으로 데이터를 읽는 데 최적화되어 있어, 연결 리스트를 정렬할 때 배열보다 훨씬 빠르게 동작합니다.
3. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선/평균/최악 시간 복잡도 | O(N log N) | 크기가 N인 배열을 매번 1/2씩 계속 나누므로 트리의 높이는 log N이 됩니다. 각 높이(단계)마다 모든 요소(N개)를 스캔하며 병합하므로 단계당 비용은 O(N)이 소요됩니다. 따라서 전체는 O(N log N)입니다. |
| 공간 복잡도 | O(N) | 병합된 부분 배열을 임시로 저장할 배열 공간이 요소 개수(N)만큼 추가로 필요합니다. (In-place 정렬이 아님) |
💡 실무 지식: 퀵 정렬 vs 병합 정렬
일반적으로 배열을 다룰 때, 메모리 복사가 불필요한 퀵 정렬(Quick Sort)이 캐시 지역성(Cache Locality) 측면에서 병합 정렬보다 평균 20% 더 빠릅니다. 하지만, 최악의 성능 하락을 절대 용납할 수 없는 시스템 커널이나 표준 라이브러리(Java의 Arrays.sort() 등)에서는 병합 정렬의 변형(Timsort 등)이 더 널리 사용됩니다.