퀵 정렬 (Quick Sort)
퀵 정렬 (Quick Sort)
퀵 정렬(Quick Sort)은 1959년 토니 호어(Tony Hoare)가 고안한 매우 빠르고 효율적인 정렬 알고리즘입니다. 피벗(Pivot)을 기준으로 배열을 작은 값과 큰 값 두 부분으로 분할(Partitioning)한 뒤, 각 부분을 재귀적으로 정렬하는 분할 정복(Divide and Conquer) 방법을 사용합니다. 범용적으로 가장 널리 쓰이는 정렬 알고리즘입니다.
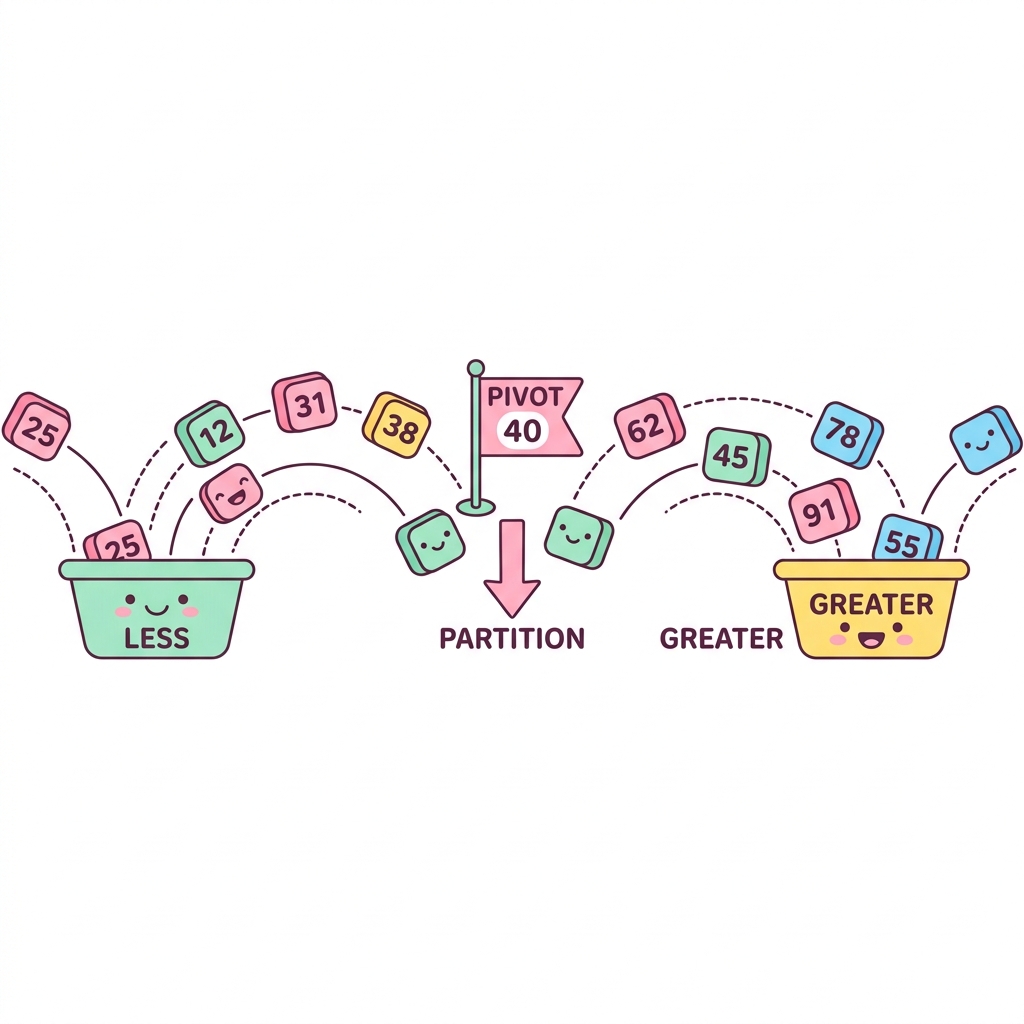
1. 퀵 정렬의 작동 원리 (Partitioning)
퀵 정렬의 핵심은 피벗(Pivot) 선정과 이를 기준으로 배열을 가르는 파티셔닝입니다.
● Pivot 선정 : 배열에서 임의의 한 요소를 피벗으로 선택합니다. (보통 첫 번째, 마지막, 또는 중간값)
● Partitioning : 피벗보다 작은 요소들은 모두 왼쪽으로, 큰 요소들은 모두 오른쪽으로 옮깁니다.
● Recursion (재귀) : 나누어진 왼쪽 배열과 오른쪽 배열에 대해 위 과정을 배열의 크기가 1이 될 때까지 반복합니다.
2. 퀵 정렬의 주요 특징
[1] 압도적인 실제 속도 (캐시 효율성)
배열 내에서 포인터를 스왑하며 내부적으로 데이터 위치를 바꾸는 제자리 정렬(In-place Sort)로 작동하므로, 메모리 캐시 지역성(Cache Locality)이 병합 정렬이나 힙 정렬보다 훨씬 뛰어나 현실 환경에서 가장 빠릅니다.
[2] 불안정 정렬 (Unstable Sort)
값이 동일한 요소들의 상대적인 위치가 파티셔닝 과정에서 뒤바뀔 수 있습니다. 순서 유지가 보장되어야 할 때는 병합 정렬이 더 선호됩니다.
[3] 최악의 경우 O(N²) 주의
배열이 이미 오름차순/내림차순으로 정렬되어 있거나 역순으로 정렬되어 있을 때 피벗을 양 끝으로 잘못 잡으면 파티셔닝이 한쪽으로만 쏠려 최악의 성능을 냅니다.
3. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선 / 평균 시간 복잡도 | O(N log N) | 피벗이 배열을 절반씩 균등하게 가를 때 가장 이상적입니다. 분할 깊이(log N) × 병합/비교 수(N). |
| 최악 시간 복잡도 | O(N²) | 피벗이 가장 큰 값이거나 가장 작은 값으로만 선정될 때, 트리 깊이가 N이 되어 O(N²) 성능으로 급감합니다. |
| 공간 복잡도 | O(log N) | 추가적인 배열 메모리는 생성하지 않으나(In-place), 재귀 호출에 따른 콜 스택 메모리가 깊이(log N)만큼 필요합니다. |
💡 실무 지식: 최악의 O(N²)를 피하는 기법
현대의 V8 자바스크립트 엔진이나 C++의 std::sort는 단순 퀵 정렬을 쓰지 않습니다. 배열의 앞, 중간, 뒤의 세 값 중 중간값을 피벗으로 고르는 Median of Three 방법이나, 재귀 깊이가 깊어지면 힙 정렬로 전환하는 인트로 정렬(Introsort) 방식을 결합하여 최악의 경우에도 항상 O(N log N)을 보장하도록 안전하게 최적화되어 있습니다.