검색 엔진의 작동 원리 (크롤링, 인덱싱, 렌더링)
검색 엔진의 작동 원리 (크롤링, 인덱싱, 렌더링)
내 웹사이트가 구글 검색 1페이지에 뜨기 위해서, 검색 엔진 봇(로봇)이 내 사이트를 평가하는 3단계 과정(Crawling → Indexing → Ranking)을 완벽히 이해해야 합니다. 구글 봇은 "크롤 버젯(Crawl Budget)" 내에서만 수집을 진행하므로 사이트를 가볍고 효율적으로 만들어야 합니다.
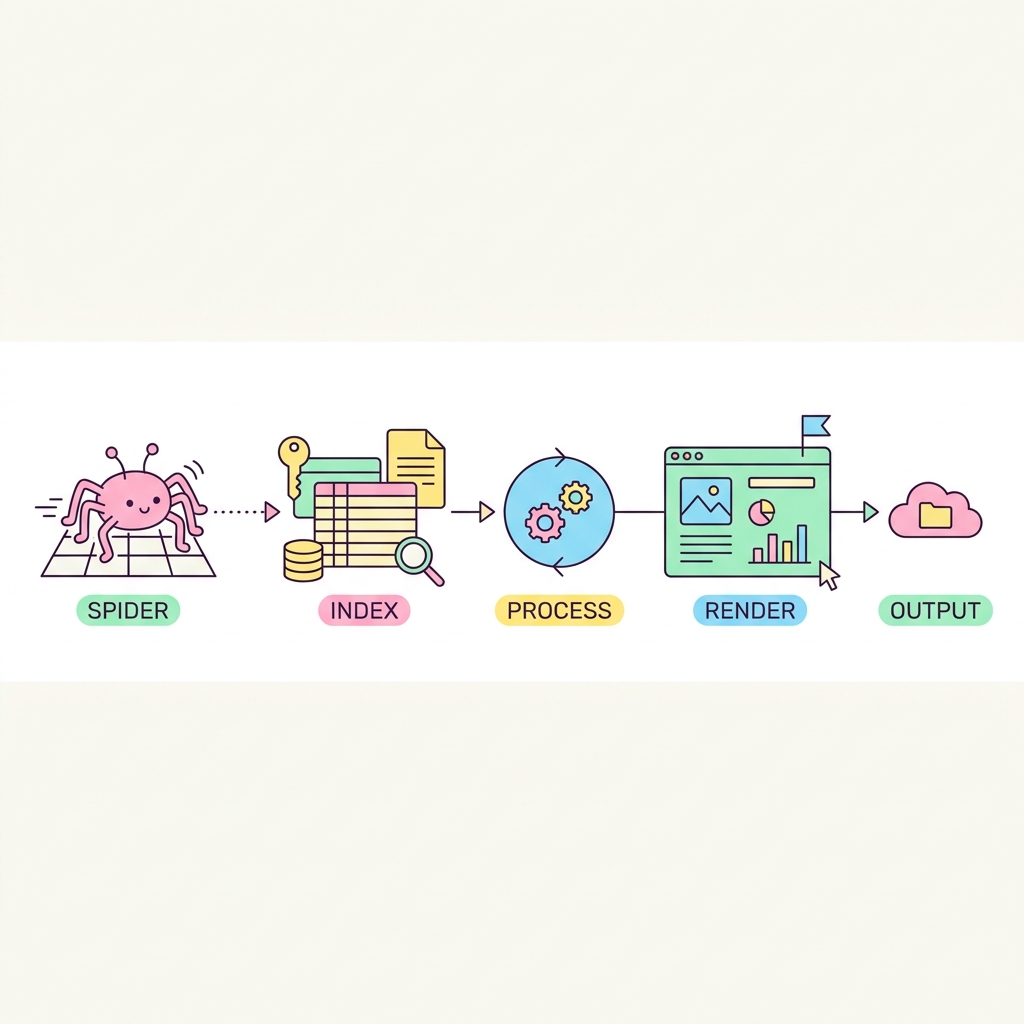
💡 핵심 비유
도서관 사서의 책 정리
사서(크롤러)가 새 책(웹페이지)을 가져와서 목차를 읽고(인덱싱), 사람들이 찾기 쉬운 베스트셀러 진열장(랭킹)에 배치하는 과정과 완벽히 일치합니다.