B-Tree & B+Tree
B-Tree & B+Tree (B-트리)
수천만 건의 데이터를 가진 MySQL, Oracle 등 데이터베이스(DB)는 어떻게 0.01초 만에 원하는 데이터를 쏙 빼올까요? 그 비밀 병기가 바로 B-Tree (Balanced Tree)와 그 발전형인 B+Tree입니다.
일반적인 이진 트리(Binary Tree)는 한 노드에 자식이 2개뿐이라 데이터가 많아지면 나무가 위아래로 매우 길어집니다. 반면 B-Tree는 하나의 노드 안에 수십~수백 개의 데이터(Key)를 구겨 넣고 가지를 여러 개 뻗는 '가로로 넓고 뚱뚱한(Fat & Shallow)' 구조를 택했습니다. 이 기발한 아이디어가 하드디스크(HDD/SSD)의 물리적 속도를 한계까지 끌어올렸습니다.
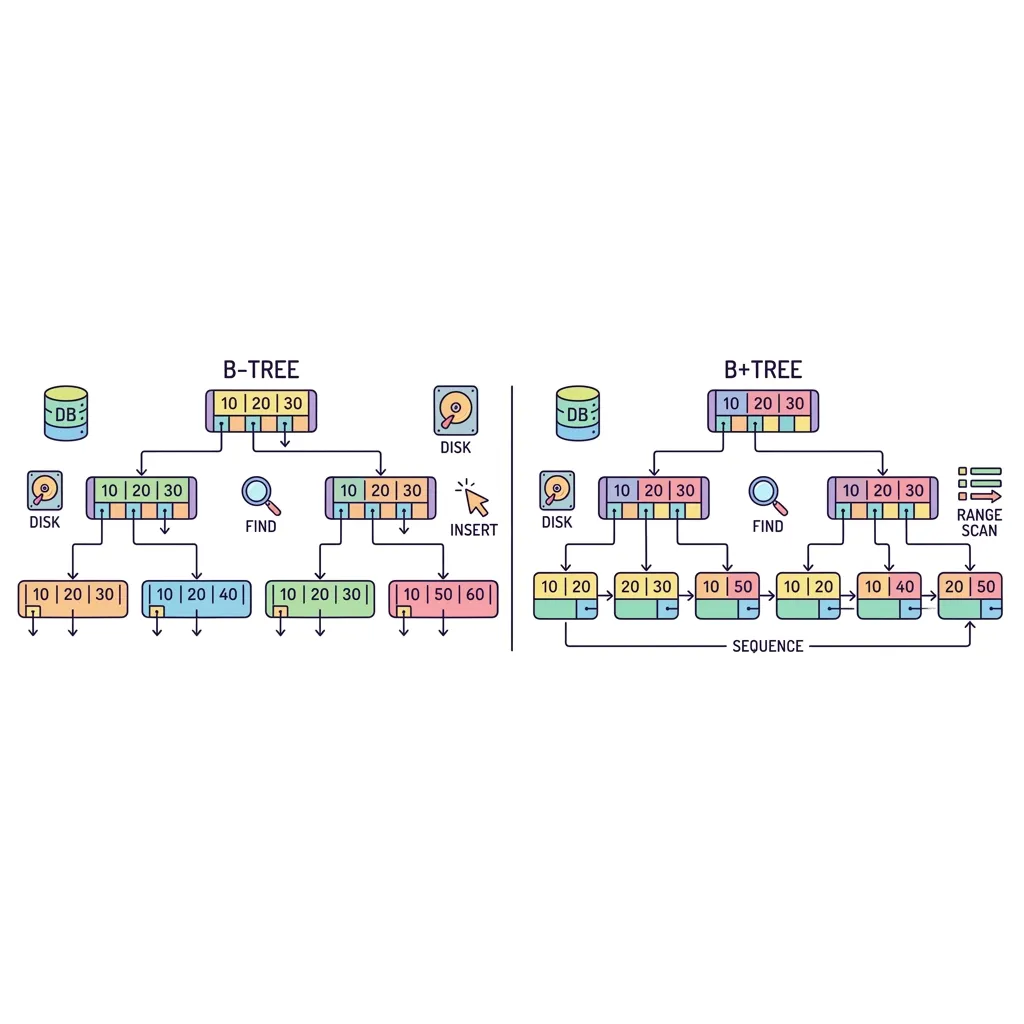
1. B-Tree의 구조: 왜 가로로 뚱뚱한가?
2. 디스크 I/O와 B-Tree의 궁합
컴퓨터에서 가장 느린 부품은 '하드디스크(SSD 포함)'입니다. 디스크에서 데이터를 한 번 퍼올릴 때마다 막대한 I/O 시간이 걸립니다.
- 이진 탐색 트리(BST): 100만 건 탐색 시 최악의 경우 트리 높이가 100만 층. 디스크를 최대 100만 번 긁어와야 함 (엄청난 속도 저하).
- B-Tree: 하나의 노드(디스크 블록 1페이지) 안에 100개의 키를 넣으면, 100갈래로 가지를 칩니다. 100만 건 데이터라도 트리 높이는 겨우 3층에 불과합니다. 즉, 디스크를 단 3번만 퍼올리면 데이터를 찾을 수 있습니다!
💡 실무 지식: B+Tree는 무엇이 다른가요?
B-Tree를 한 번 더 개량한 것이 B+Tree (MySQL InnoDB 기본 인덱스)입니다.
B-Tree는 모든 노드에 실제 데이터가 들어있지만, B+Tree는 중간 노드에는 이정표(Key)만 두고, 실제 데이터는 무조건 맨 아랫바닥(리프 노드)에만 몰아넣습니다.
그리고 바닥에 깔린 리프 노드들끼리 연결 리스트(Linked List)로 쭈욱 연결해 두었습니다. 덕분에 "10번부터 50번까지 쭉 가져와!" 같은 범위 검색(Range Scan)을 할 때, 트리를 오르락내리락 할 필요 없이 바닥에서 기차처럼 옆으로 쭉 긁어오기만 하면 되므로 성능이 폭발적으로 상승합니다.