데이터베이스와 RDBMS의 이해
데이터베이스와 RDBMS의 이해
데이터베이스(DB)는 단순히 많은 양의 데이터를 모아둔 '창고'입니다. 하지만 창고에 물건을 마구잡이로 쌓아두면 나중에 찾기 어렵겠죠?
그래서 데이터를 엑셀의 표(Table)처럼 구조화하여 관리하고, 규칙에 따라 빠르고 안전하게 꺼내 쓸 수 있도록 도와주는 전문 관리 소프트웨어가 탄생했는데 이를 RDBMS(관계형 데이터베이스 관리 시스템)라고 부릅니다. 오라클, MySQL, PostgreSQL 등이 대표적입니다.
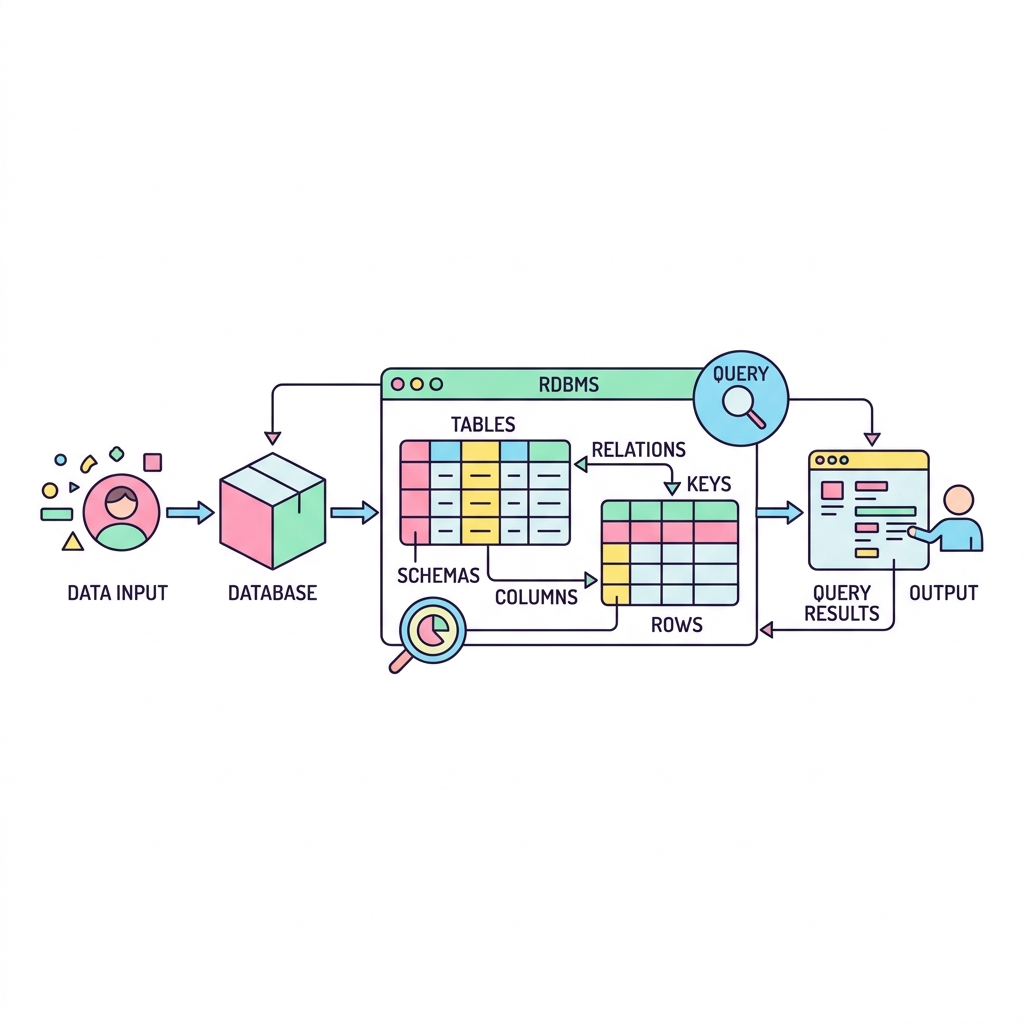
💡 핵심 비유: 도서관의 책들과 유능한 사서
데이터 자체(DB)는 도서관에 꽂혀 있는 수만 권의 '책'과 같습니다. RDBMS는 이 책들을 장르별, 저자별로 체계적으로 분류하고, 사용자가 "해리포터 찾아줘"라고 요청하면 1초 만에 책을 꺼내다 주는 유능한 사서(관리 시스템)입니다.
🗂️ 테이블 간의 관계(Relation) 구조
표준 SQL(ANSI SQL)이란?
표준 SQL(ANSI SQL)이란?
RDBMS는 오라클, MySQL, SQL Server 등 다양한 회사에서 만듭니다. 만약 각자 자기들만의 언어로만 데이터를 뽑게 한다면, 개발자는 시스템이 바뀔 때마다 언어를 새로 배워야 하는 끔찍한 일이 발생합니다.
이 문제를 해결하기 위해 ANSI(미국 국립 표준 협회)에서 표준 SQL 규격을 제정했습니다. 이 표준만 익히면 어떤 회사의 DB를 쓰더라도 80~90% 동일한 문법으로 데이터를 조작할 수 있습니다.
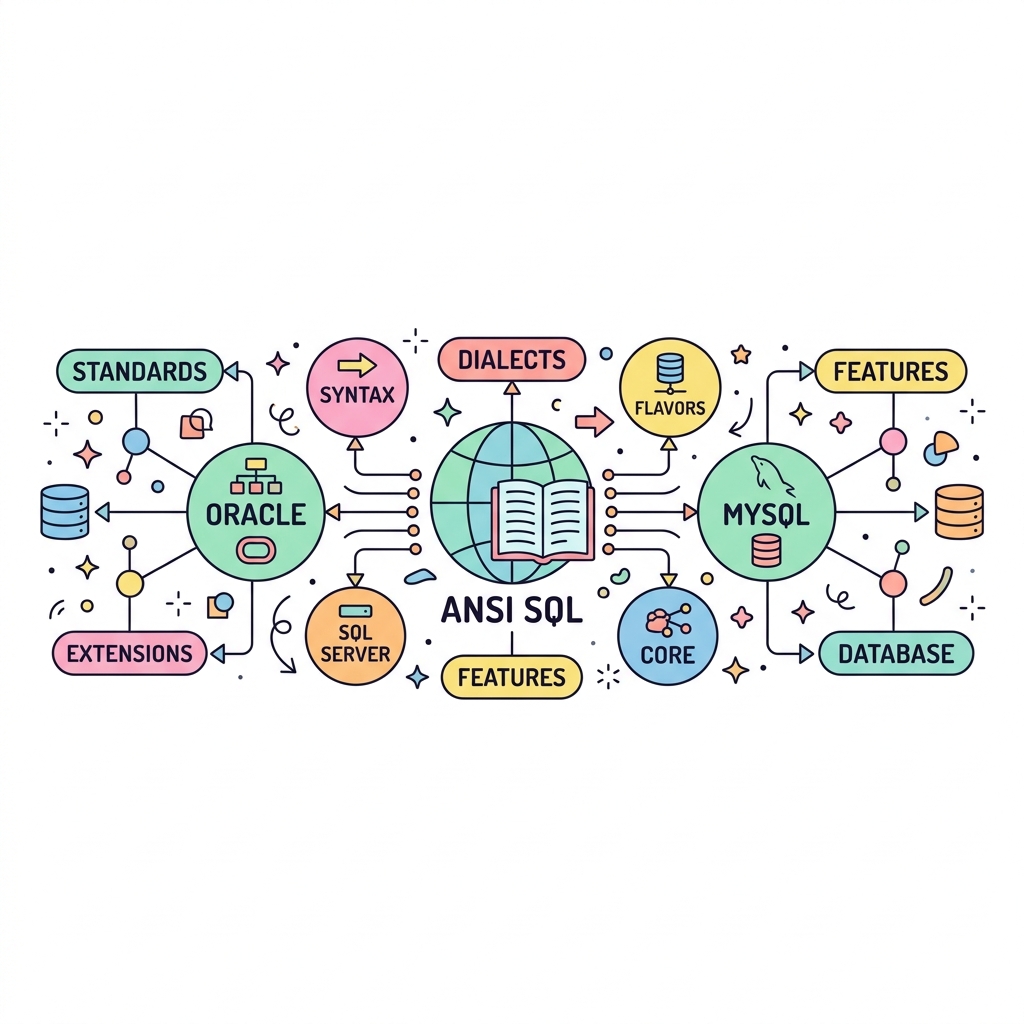
💡 핵심 비유: 세계 공용어(영어)와 지역 방언(사투리)
표준 SQL은 전 세계 어디서나 통하는 공용어(영어)입니다. SELECT, FROM, WHERE 같은 뼈대가 여기에 속합니다. 하지만 각 DB 벤더마다 더 빠르고 편리한 자기들만의 특별한 함수나 문법을 추가로 제공하는데, 이를 방언(Dialect)이라고 합니다. (예: 오라클의 NVL, MySQL의 IFNULL)
🌐 표준 SQL과 방언의 조화
학습 환경 구축
학습 환경 구축
데이터베이스에 접속해서 SQL을 작성하고 실행하려면 크게 두 가지가 필요합니다. 데이터를 보관하고 쿼리를 처리해 주는 DB 서버 엔진(오라클, MySQL 서버 등)과, 우리가 그 서버에 원격으로 접속하여 편하게 코드를 칠 수 있게 도와주는 클라이언트 툴(DBeaver, SQL Developer, DataGrip 등)입니다.
실무에서는 주로 리눅스 서버나 AWS RDS에 DB 엔진을 띄워두고, 내 PC에 설치된 클라이언트 툴로 원격 접속하여 작업을 진행합니다.
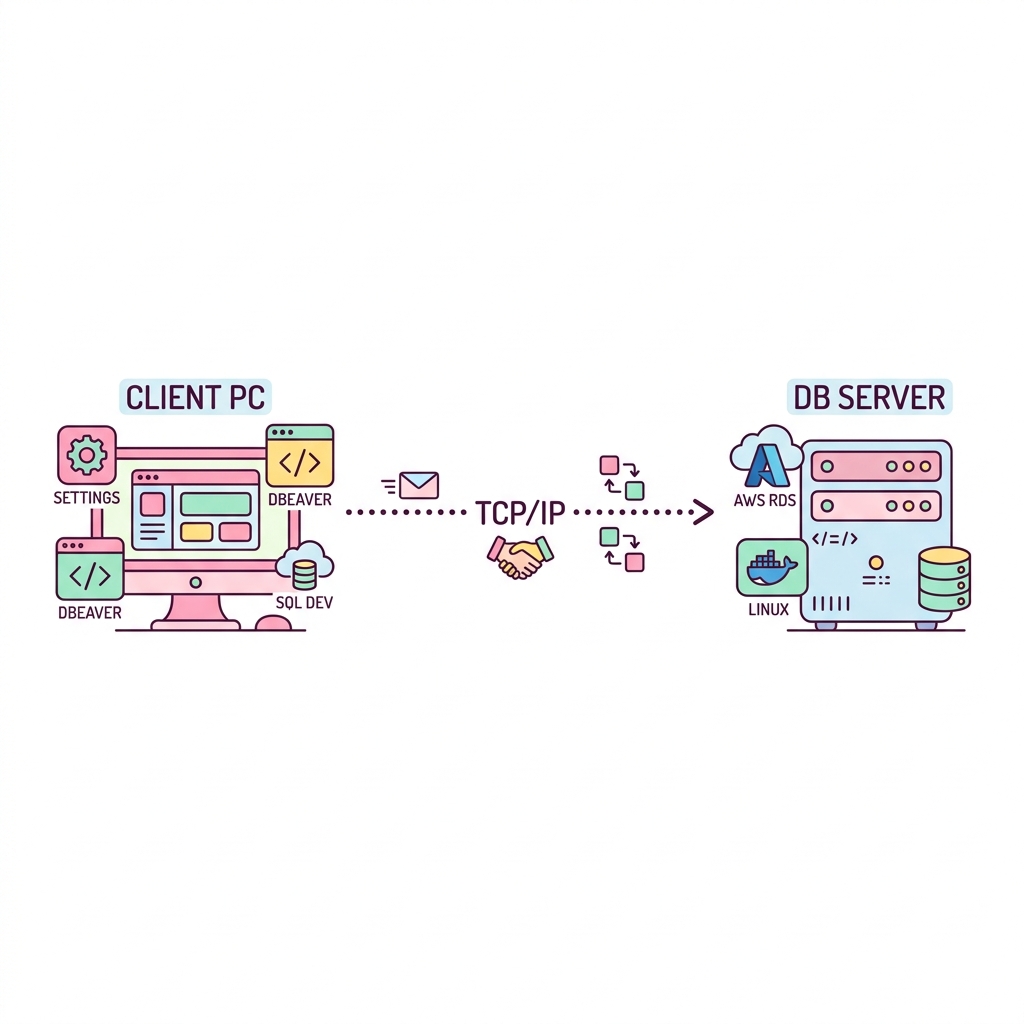
💡 핵심 비유: 요리사의 주방과 리모컨
DB 서버는 식재료가 가득한 주방이자 가스레인지입니다. 직접 열을 뿜으며 요리를 하죠. 클라이언트 툴(DBeaver)은 거실에서 주방의 오븐을 조작하는 리모컨과 같습니다. 내 PC에서 SQL(명령어)을 입력하면, 네트워크를 타고 주방(서버)으로 날아가 요리된 결과(데이터)만 내 모니터로 가져와서 예쁘게 표로 보여줍니다.
🔌 3-Tier 아키텍처와 접속 원리
SELECT와 FROM
SELECT와 FROM
데이터베이스에서 데이터를 조회하는 가장 기본이자 90% 이상을 차지하는 핵심 구문입니다.
FROM 절에는 데이터를 꺼내올 '표(테이블)'의 이름을 지정하고, SELECT 절에는 그 표 중에서 내가 보고 싶은 '열(컬럼)'의 이름을 지정합니다. 모든 컬럼을 보고 싶다면 * (별표, 애스터리스크) 기호를 사용합니다.
💡 핵심 비유: 식당 메뉴판에서 원하는 음식 주문하기
FROM은 "어느 식당(테이블)에서 먹을 것인가?"를 정하는 것이고, SELECT는 "그 식당의 메뉴판 중 어떤 메뉴(컬럼)를 달라고 할 것인가?"를 주문하는 것과 같습니다.
예: SELECT 이름, 나이 FROM 회원테이블; -> "회원테이블 식당에서, 이름과 나이 메뉴만 주세요!"
🔍 데이터 추출(Projection)
WHERE 절
WHERE 절 (데이터 필터링)
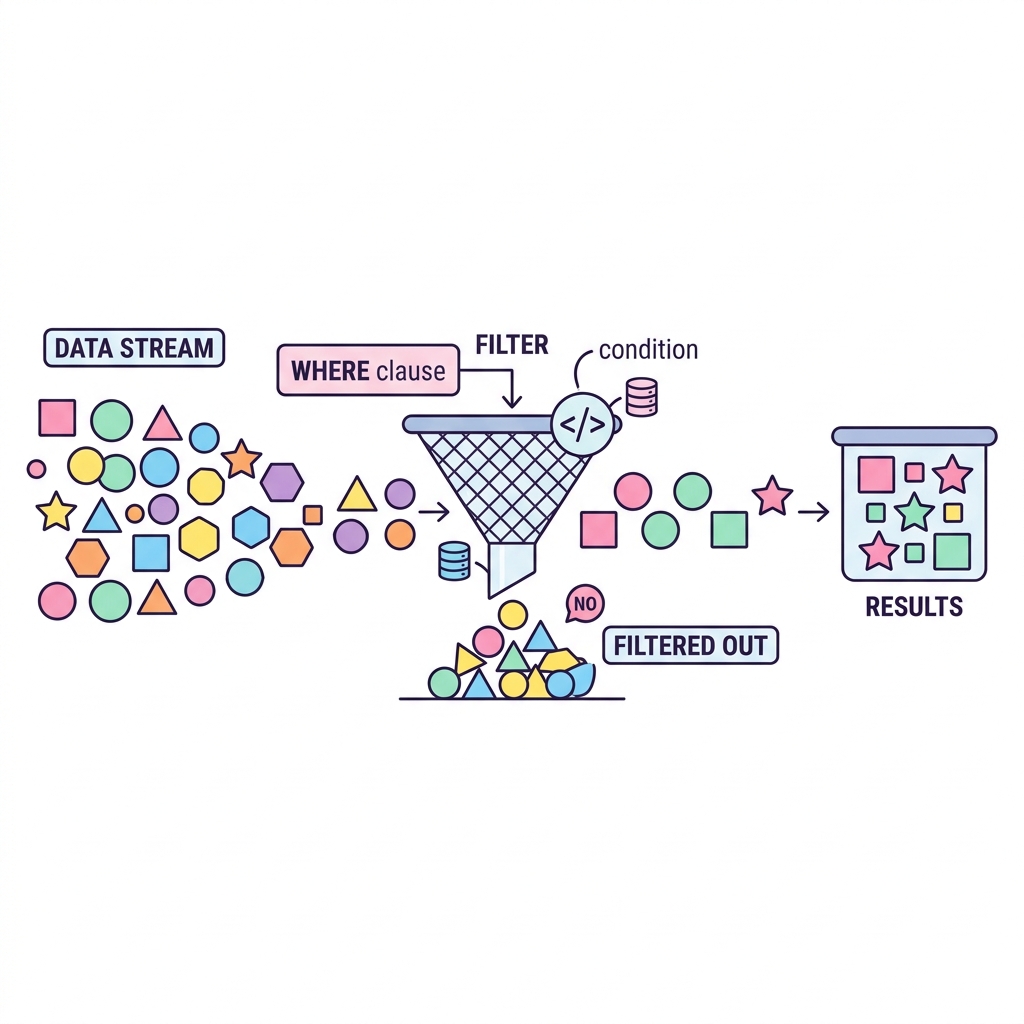
만약 회사에 직원이 10만 명이 있다면 SELECT * FROM 직원 쿼리는 10만 줄의 데이터를 모조리 화면에 뿌리며 서버를 뻗게 만들 수 있습니다.
이때 WHERE 절을 사용하여 "급여가 5000 이상인 사람" 또는 "부서가 '영업부'인 사람"처럼 특정 조건을 부여하면, DB가 그 조건에 맞는 데이터만 쏙쏙 골라내어(필터링하여) 결과로 반환해 줍니다.
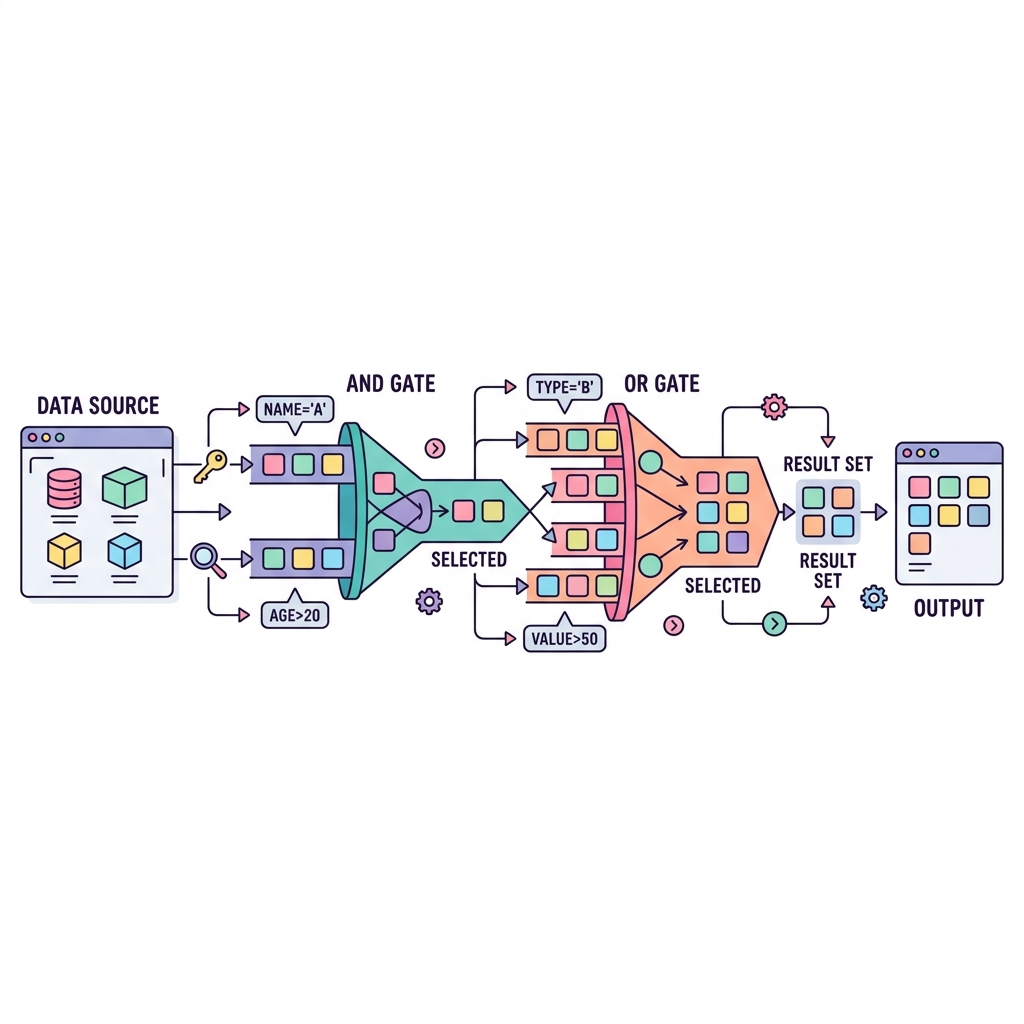
💡 핵심 비유: 촘촘한 채반으로 알맹이 걸러내기
수만 개의 데이터 덩어리를 WHERE 절이라는 채반(필터) 위에 쏟아붓는다고 생각해 보세요. 조건식(예: 나이 >= 20)이라는 채반의 구멍 크기를 통과하는 데이터(True)만 최종 결과 그릇에 담기게 됩니다.
✂️ 필터링(Selection) 작동 원리
📋 자주 쓰이는 필터링 연산자
| 연산자 | 설명 | 사용 예시 |
|---|---|---|
| =, !=, >, < | 일반적인 비교 연산자 (같다, 다르다, 크다 등) | WHERE age >= 20 |
| IN (A, B, C) | 목록 내에 값이 포함되어 있는지 확인 | WHERE dept IN ('영업', '인사') |
| BETWEEN A AND B | 값이 A와 B 범위 사이에 있는지 확인 (A, B 포함) | WHERE price BETWEEN 100 AND 200 |
ORDER BY
ORDER BY
데이터를 단순히 가져오는 것을 넘어, 원하는 기준에 따라 정렬(Sort)하는 것은 가장 기본적이면서도 중요한 작업입니다. 금액이 높은 순, 이름의 가나다순, 혹은 최신 날짜순 등 데이터를 보기 좋게 정리해 주는 마법의 키워드가 바로 ORDER BY입니다.
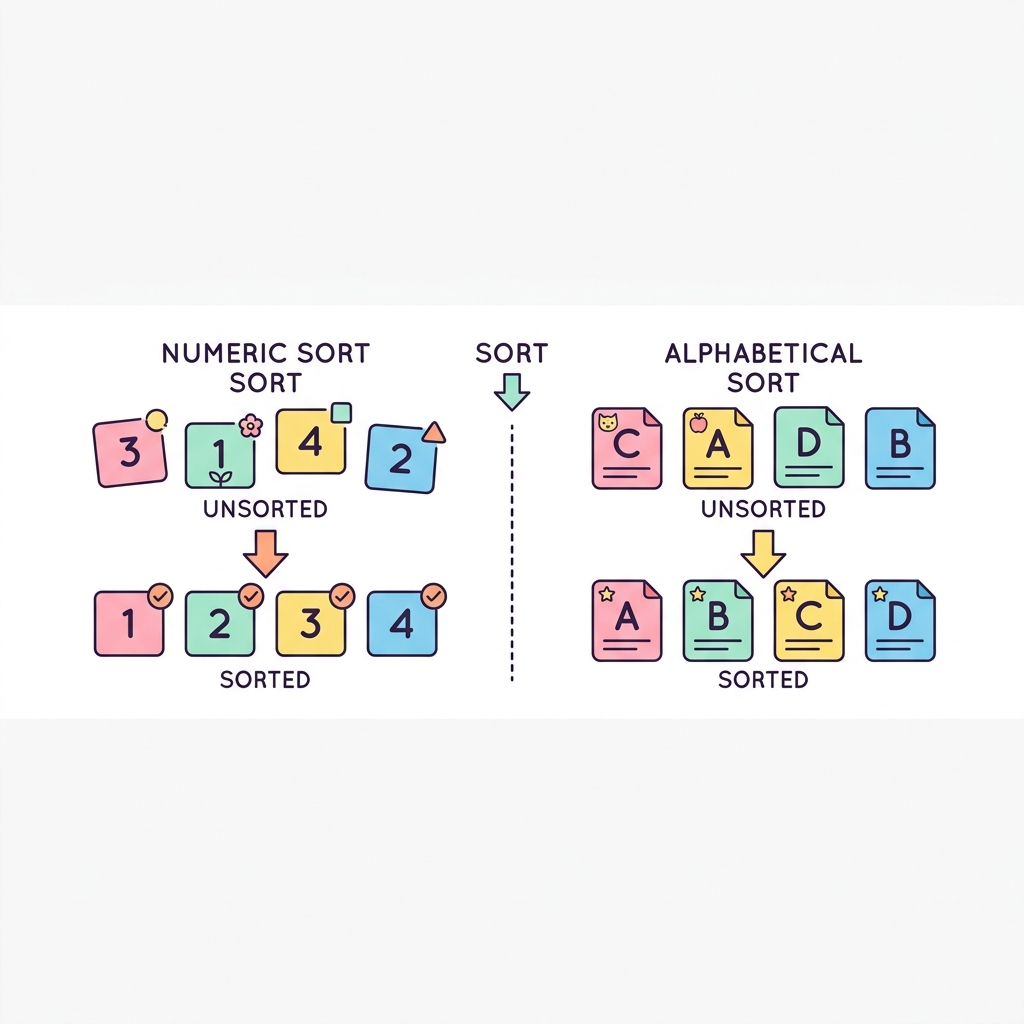
💡 핵심 비유
명부 정리
마치 무작위로 쌓여 있는 학생 명부를 출석 번호순(오름차순) 혹은 성적순(내림차순)으로 다시 깔끔하게 재배열하는 작업과 같습니다.
🧩 원리 이해하기
LIMIT / OFFSET
LIMIT / OFFSET
웹 게시판이나 쇼핑몰 리스트를 보면 데이터가 한 번에 수만 개씩 나오지 않고 10개 혹은 20개씩 끊어서(페이징) 보입니다. 수백만 건의 데이터 중 우리가 필요한 딱 10건만 빠르게 가져오기 위해 사용하는 필수 문법이 바로 LIMIT과 OFFSET입니다.
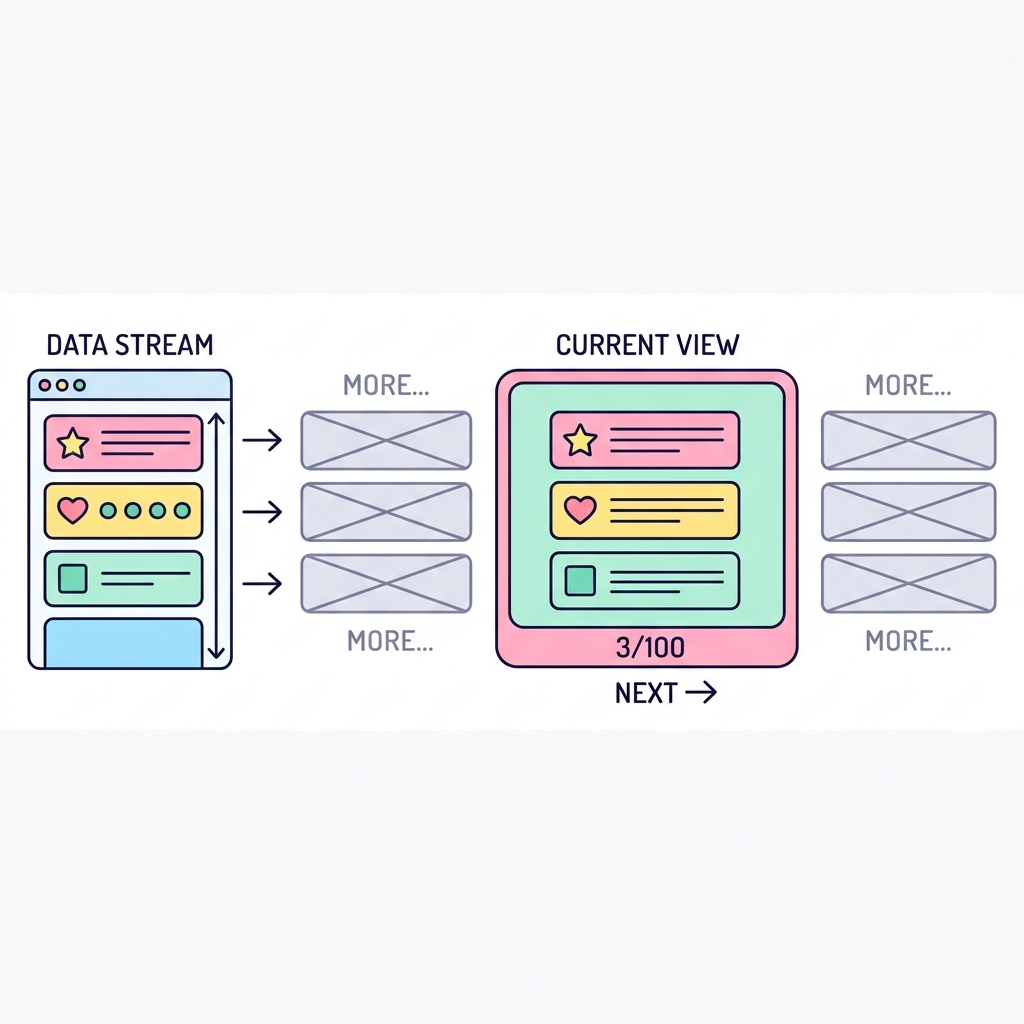
💡 핵심 비유
책의 페이지 넘기기
수만 페이지의 백과사전에서 OFFSET 20(앞 20쪽 건너뛰기) 한 뒤 LIMIT 10(10장만 읽기)을 통해 21쪽부터 30쪽까지만 정확하게 뽑아 읽는 것과 같습니다.
🧩 원리 이해하기
다양한 필터링 기법
다양한 필터링 기법
기본적인 =, <, > 외에도 SQL은 데이터를 찾아내는 강력한 무기들을 제공합니다. 특정 패턴(글자)을 포함하는지 찾는 LIKE, 범위 내의 값인지 확인하는 BETWEEN, 비어있는 값인지 확인하는 IS NULL 등이 있습니다.

💡 핵심 비유
탐정의 돋보기
"김씨 성을 가진 사람", "1월부터 3월 사이에 가입한 사람", "아직 전화번호를 등록하지 않은 사람"을 돋보기로 정밀하게 수사하여 찾아내는 과정입니다.
🧩 원리 이해하기
문자열 함수
문자열 함수
데이터베이스에 저장된 텍스트(문자열)를 그대로 쓸 수도 있지만, 소문자로 바꾸거나(LOWER), 특정 단어만 잘라내거나(SUBSTR), 다른 단어로 교체(REPLACE)해야 할 때가 있습니다. 이런 조작을 가능하게 해주는 것이 문자열 함수입니다.
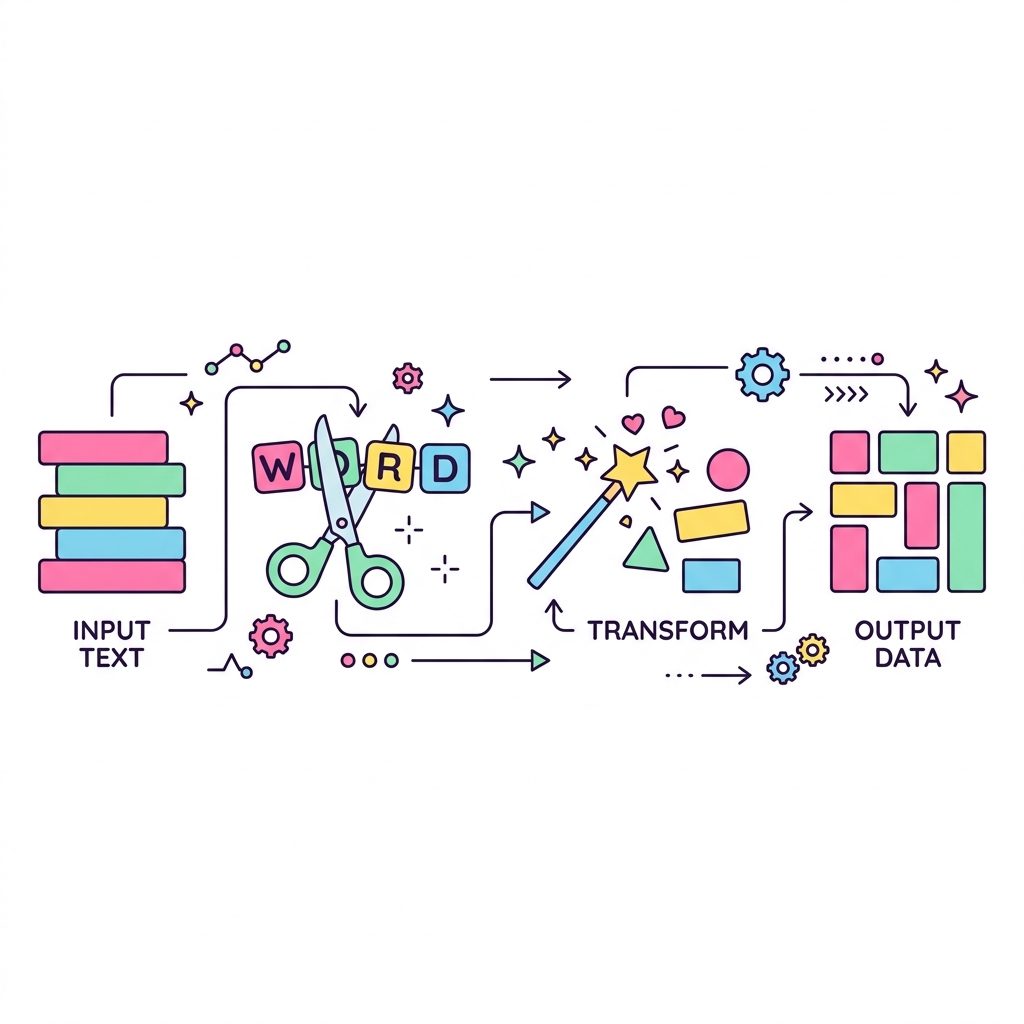
💡 핵심 비유
마법의 텍스트 가위와 풀
원본 문서를 훼손하지 않고, 복사본을 가위로 오려내고 풀로 붙여서 화면에 예쁘게 보여주는 조작 마법입니다.
🧩 원리 이해하기
숫자 및 날짜 함수
숫자 및 날짜 함수
데이터 분석과 리포팅에서 숫자 계산(반올림, 올림 등)과 날짜 계산(포맷 변환, 한 달 더하기, 일수 차이 계산 등)은 필수불가결합니다. 오라클의 TO_CHAR나 MySQL의 DATE_FORMAT 등은 가장 자주 쓰이는 포맷팅 함수입니다.

💡 핵심 비유
스마트 계산기와 달력
복잡한 소수점을 보기 좋게 둘째 자리에서 반올림하고, "20260521" 같은 암호 같은 날짜 데이터를 "2026년 5월 21일"로 친절하게 번역해 주는 도구입니다.
🧩 원리 이해하기
조건 논리 처리
조건 논리 처리
데이터를 단순히 가져오기만 하는 것이 아니라, 상황에 따라 다른 값을 부여하고 싶을 때가 있습니다. 프로그래밍 언어의 if-else문과 동일한 역할을 SQL에서는 CASE WHEN 구문이 담당합니다.
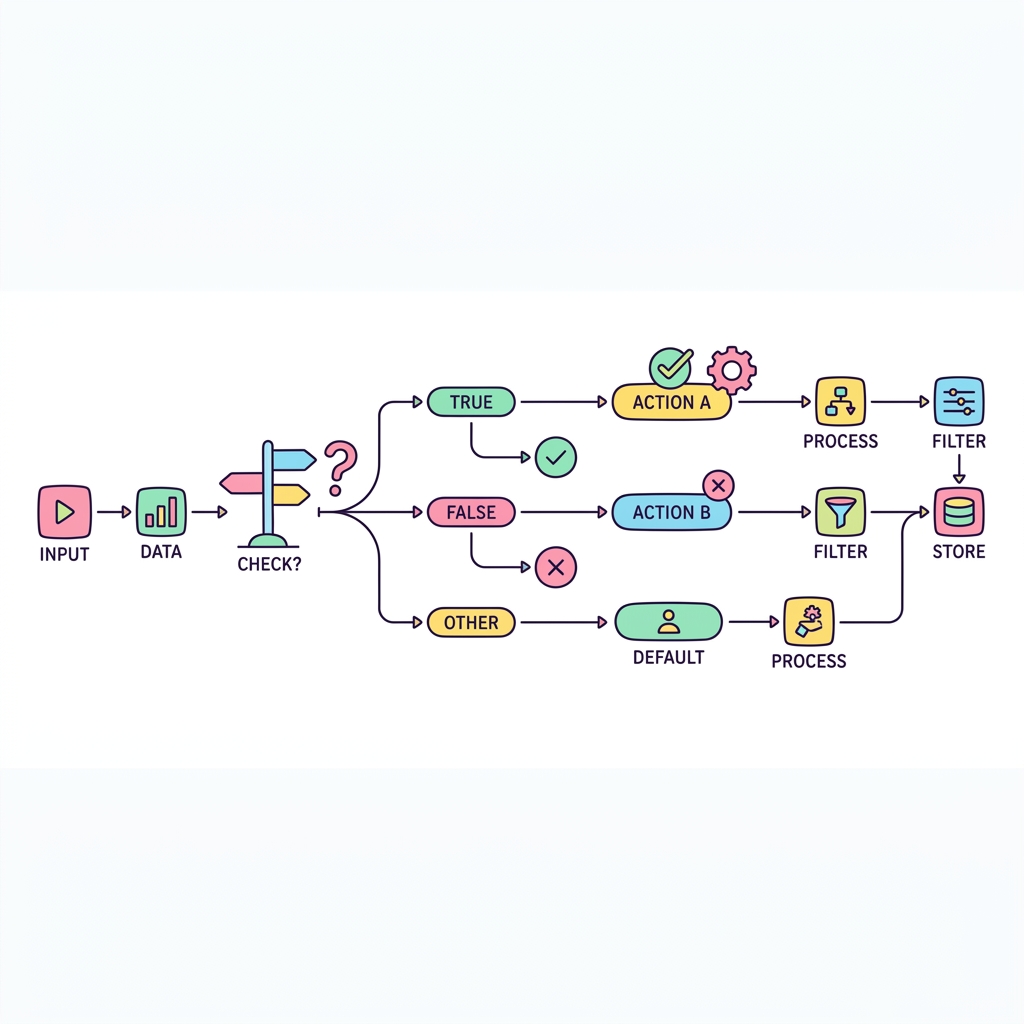
💡 핵심 비유
컨베이어 벨트의 분배기
사과가 지나가면 A박스로, 바나나가 지나가면 B박스로 자동 분류해 주는 스마트 스위치와 같습니다.
🧩 원리 이해하기
집계 함수
집계 함수
데이터가 수만 건이 있을 때, 이를 건건이 보는 것이 아니라 전체 데이터의 총합, 평균, 최댓값, 최솟값, 갯수 등을 구해야 할 때가 있습니다. 이를 집계(Aggregation) 함수라고 부릅니다. (SUM, AVG, MAX, MIN, COUNT 등)
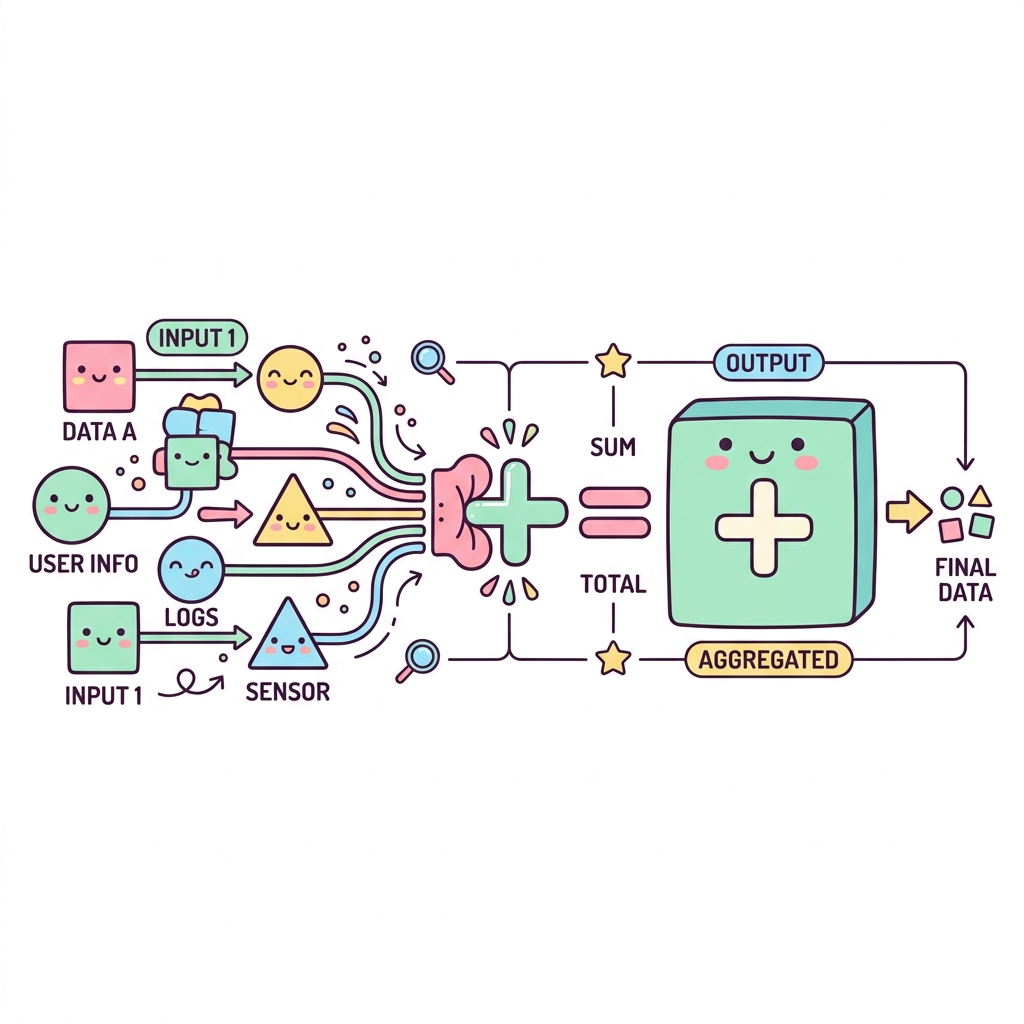
💡 핵심 비유
블렌더(믹서기)
수많은 개별 과일(데이터)들을 통째로 갈아서 한 컵의 주스(단일 결과값)로 압축해 내는 과정입니다.
🧩 원리 이해하기
GROUP BY
GROUP BY
집계 함수(SUM, COUNT 등)가 무조건 전체 데이터를 하나로 뭉친다면, GROUP BY는 데이터를 특정 기준에 따라 끼리끼리 그룹화한 뒤 집계합니다. 예를 들어 "부서별" 평균 급여, "월별" 가입자 수를 구할 때 필수적입니다.
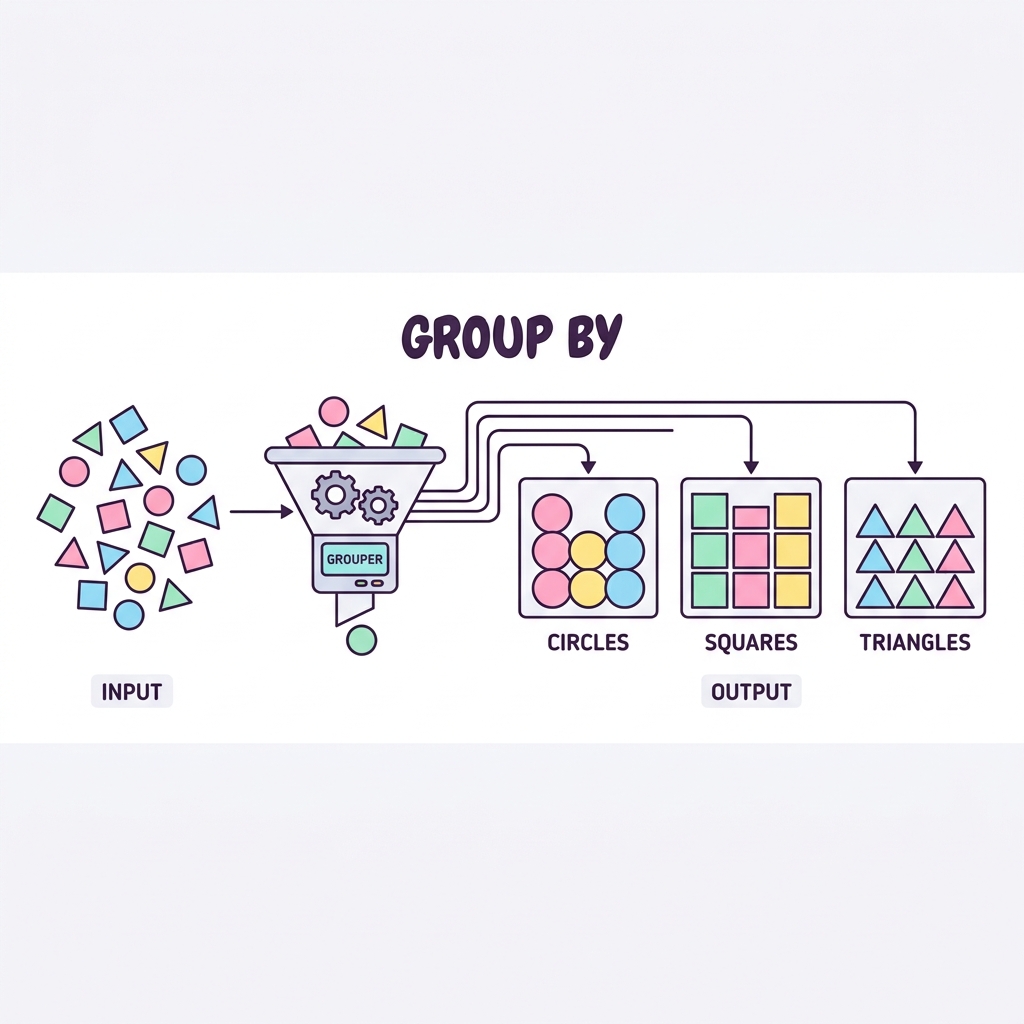
💡 핵심 비유
동전 분류기
한 뭉치의 동전을 기계에 넣으면 100원짜리, 500원짜리 등 종류별로 각각의 통에 나누어 담아주는 것과 똑같습니다.
🧩 원리 이해하기
HAVING
HAVING
WHERE가 데이터를 하나씩(Row) 검사해서 필터링한다면, HAVING은 그룹핑이 다 끝난 결과(Group)를 대상으로 필터링을 수행합니다. "부서별 평균 급여가 5000 이상인 부서만" 찾을 때는 WHERE가 아니라 HAVING을 써야 합니다.
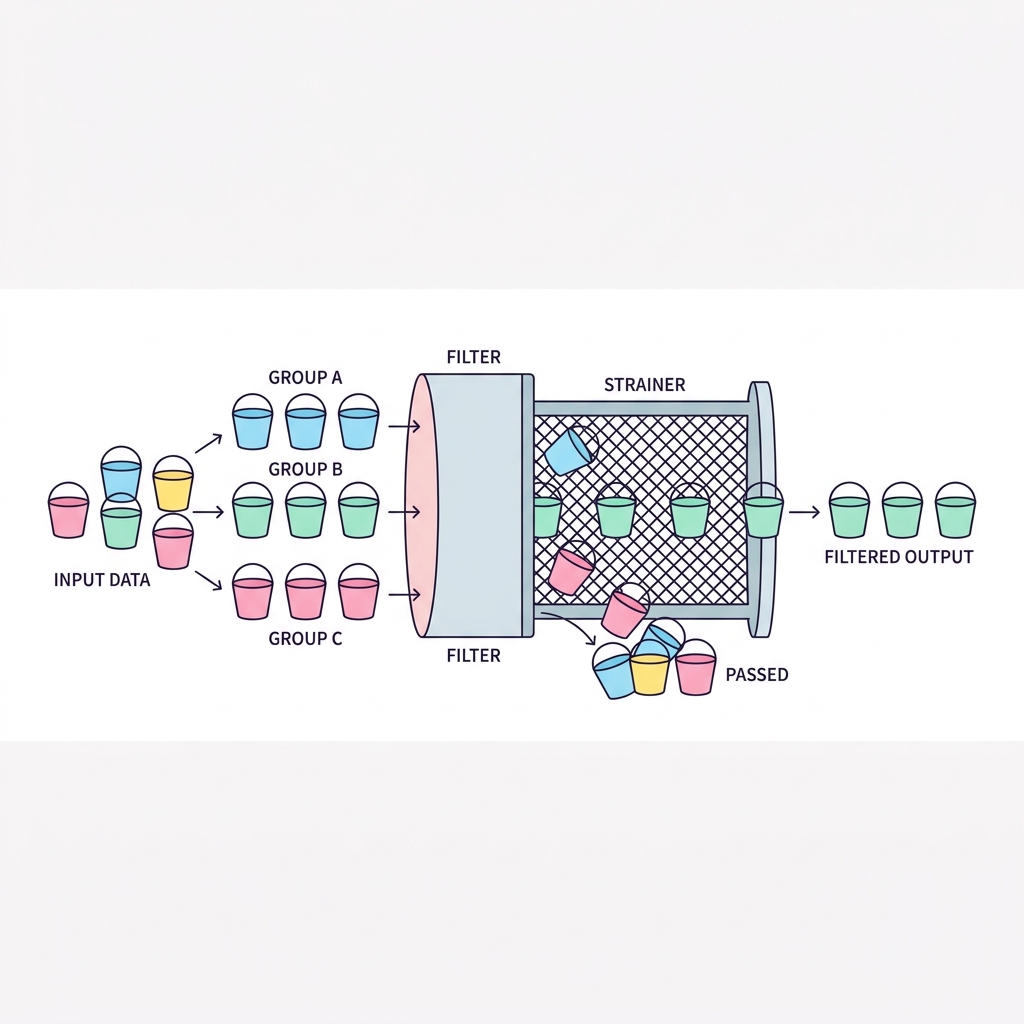
💡 핵심 비유
묶음 상품 전용 검사기
사과를 바구니에 담는 과정에서 썩은 사과를 버리는 건 WHERE, 사과를 다 담고 나서 무게가 5kg 미만인 바구니 전체를 버리는 건 HAVING입니다.
🧩 원리 이해하기
관계형 데이터베이스와 JOIN의 필요성
관계형 데이터베이스와 JOIN의 필요성
실제 세계의 서비스에서는 모든 데이터를 하나의 큰 표(엑셀)에 때려넣지 않습니다. 데이터의 중복을 막고 효율적으로 관리하기 위해 여러 개의 테이블로 쪼개서(정규화) 저장합니다. 그리고 필요할 때 연결 고리(Key)를 이용해 다시 합쳐서 보는데, 이 조립 마법이 바로 JOIN입니다.

💡 핵심 비유
퍼즐 맞추기
고객 정보 테이블(이름, 주소)과 주문 정보 테이블(상품명, 결제금액)이라는 두 개의 퍼즐 조각을 '고객 ID'라는 공통된 홈(Key)을 통해 하나로 결합하는 과정입니다.
🧩 원리 이해하기
내부 조인 (INNER JOIN)
내부 조인 (INNER JOIN)
가장 흔하게 쓰이는 JOIN 방식입니다. 두 개의 테이블을 연결할 때, 연결 고리(Key)가 양쪽 테이블 모두에 존재하는 데이터만 골라서 가져옵니다. 한쪽에라도 데이터가 없으면 결과에서 완전히 누락됩니다.

💡 핵심 비유
벤 다이어그램의 교집합
소개팅 매칭 시스템에서 "남자가 찾는 조건"과 "여자가 찾는 조건"이 정확히 일치하여 맺어진 쌍(커플)만 결과로 보여주는 것과 같습니다.
🧩 원리 이해하기
외부 조인 (LEFT, RIGHT, FULL OUTER JOIN)
외부 조인 (OUTER JOIN)
양쪽에 데이터가 있어야만 나오는 INNER JOIN과 달리, 기준이 되는 한쪽 테이블의 데이터는 무조건 전부 다 가져오고 싶을 때 사용합니다. 매칭되는 상대방 데이터가 없으면 빈칸(NULL)으로 채워서 가져옵니다. 기준이 왼쪽이면 LEFT JOIN입니다.

💡 핵심 비유
학교 출석부와 동아리 명부
출석부(LEFT)를 기준으로 동아리 명부(RIGHT)를 조인하면, 동아리에 가입하지 않은 학생도 결과에는 나오며 소속 동아리 칸만 NULL로 비워지게 됩니다.
🧩 원리 이해하기
교차 조인과 셀프 조인
교차 조인과 셀프 조인
다른 테이블이 아니라 자기 자신과 JOIN하는 것을 셀프 조인(SELF JOIN)이라고 합니다. 예를 들어, 한 테이블에 "직원"과 "그 직원의 매니저 번호"가 같이 있을 때, 매니저의 진짜 이름을 찾기 위해 자기 자신의 테이블을 한 번 더 참조해야 할 때 쓰입니다.
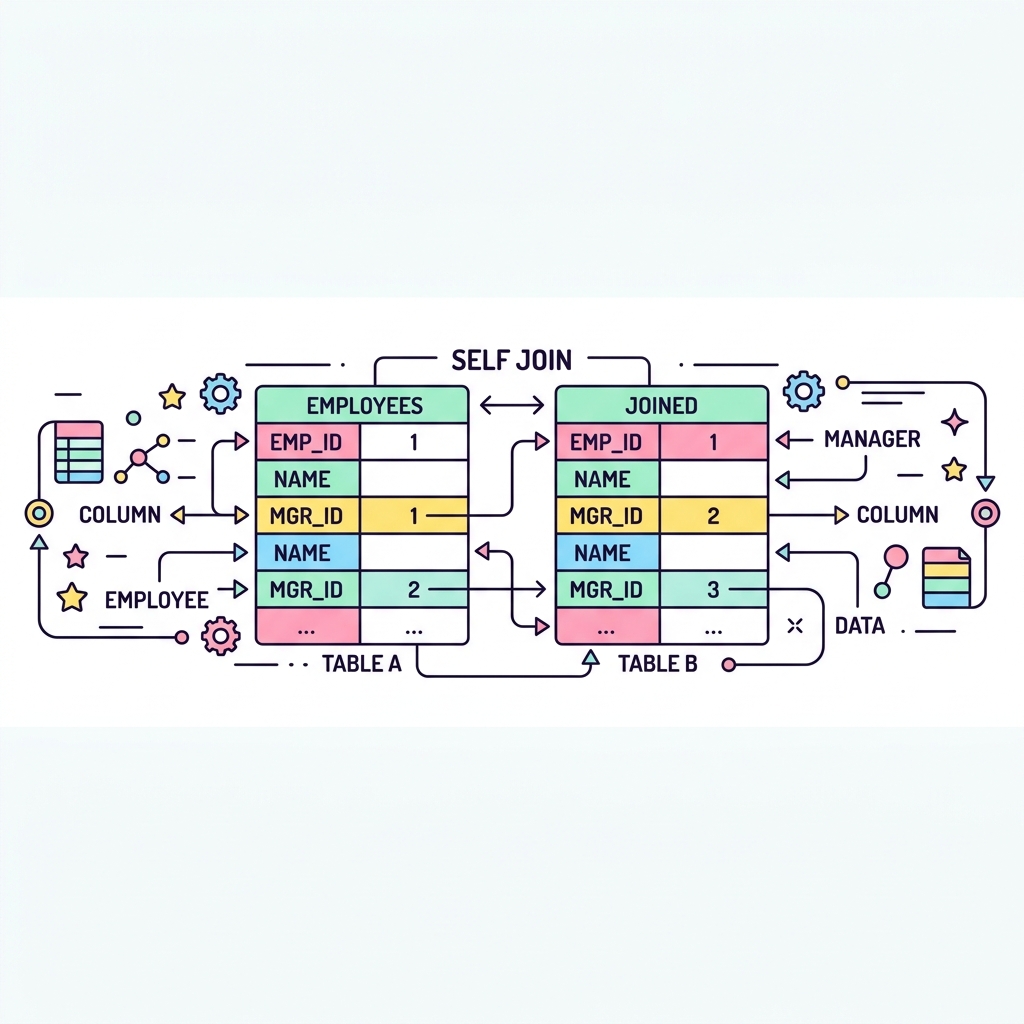
💡 핵심 비유
가계도 혹은 족보 추적기
사원 대장에서 내 매니저 번호를 확인한 뒤, 다시 그 사원 대장(자신)을 펼쳐서 그 번호를 가진 사람의 이름을 찾는 것과 같습니다.
🧩 원리 이해하기
단일행과 다중행 서브쿼리
단일행과 다중행 서브쿼리
서브쿼리(Subquery)란 메인 쿼리 안에 포함된 또 다른 쿼리입니다. 어떤 데이터를 찾기 위해 사전 조사가 필요할 때 유용합니다. 예를 들어 "회사 전체 평균 급여보다 많이 받는 사람"을 찾으려면, 먼저 "평균 급여를 구하는 쿼리(사전 조사)"를 메인 쿼리의 조건절(WHERE) 안에 넣어야 합니다.
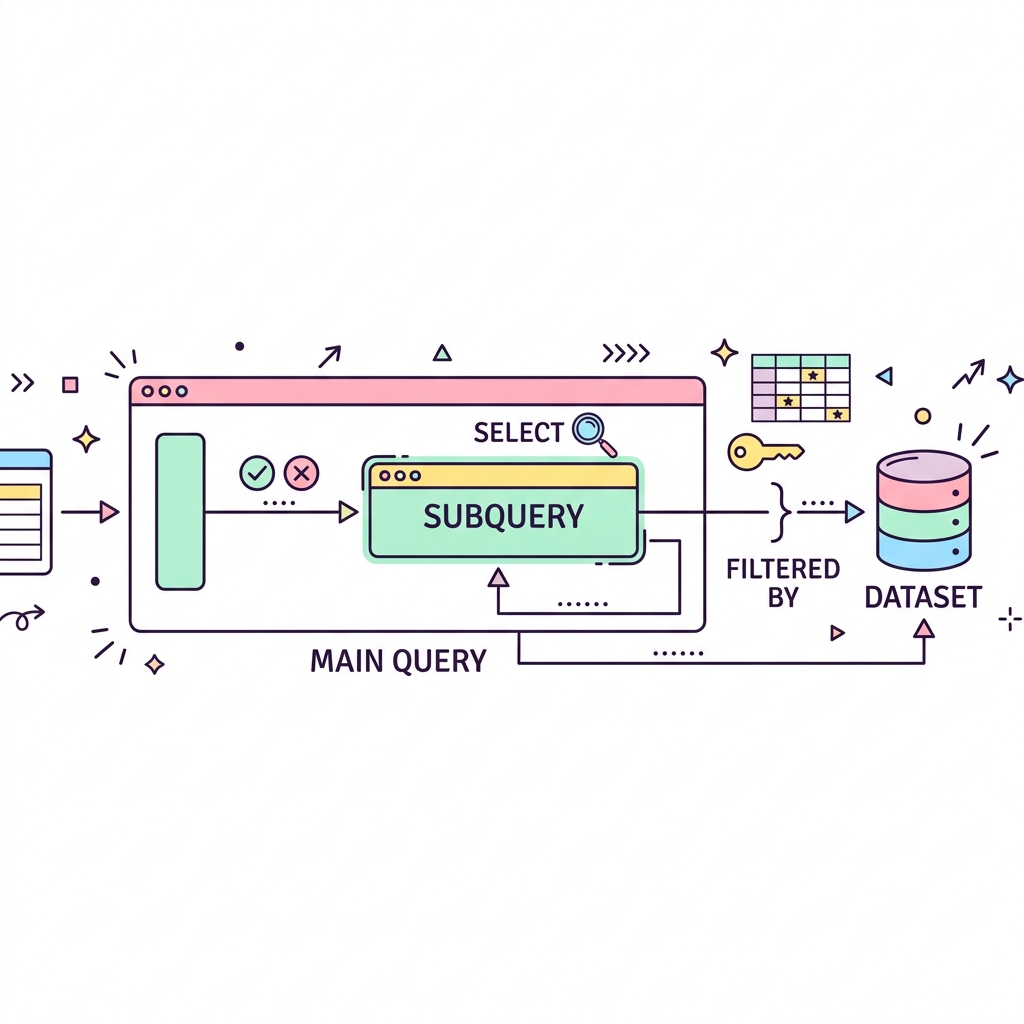
💡 핵심 비유
마트 심부름 속의 미션
어머니가 "슈퍼에 가서 제일 싼 라면을 사와라"라고 했을 때, 1단계로 "무슨 라면이 제일 싼지 확인(서브쿼리)"하고, 2단계로 "그 라면을 구매(메인쿼리)"하는 논리입니다.
🧩 원리 이해하기
인라인 뷰와 스칼라 서브쿼리
인라인 뷰와 스칼라 서브쿼리
서브쿼리를 사용하는 위치에 따라 부르는 이름이 다릅니다. FROM 절에 괄호를 쳐서 가상의 임시 테이블을 즉석으로 만들어내는 것을 인라인 뷰(Inline View)라고 부르며, SELECT 절에서 하나의 컬럼 값처럼 계산해내는 것을 스칼라 서브쿼리(Scalar Subquery)라고 부릅니다.
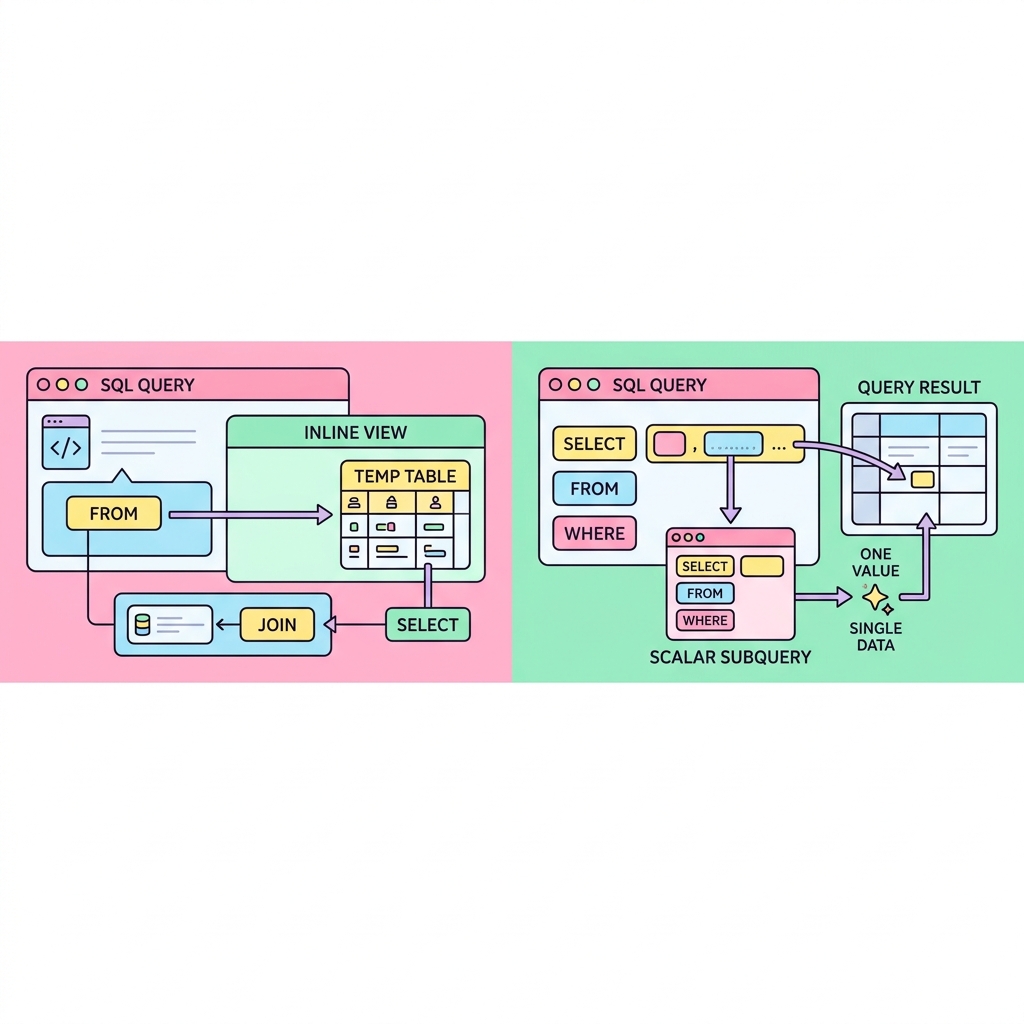
💡 핵심 비유
즉석 요리 밀키트
DB에 정식 테이블로 저장되어 있지 않지만, FROM 절에서 실시간으로 쿼리를 돌려 튀어나온 결과셋을 마치 원래 있던 테이블인 것처럼 임시로 사용하는 기술입니다.
🧩 원리 이해하기
연관 서브쿼리와 EXISTS 연산자
연관 서브쿼리와 EXISTS 연산자
EXISTS는 서브쿼리의 결과가 "단 한 건이라도 존재하는가?"만을 확인하는 아주 빠르고 효율적인 연산자입니다. 메인 쿼리의 데이터와 서브 쿼리의 데이터를 한 줄씩 엮어서 확인하는 연관 서브쿼리(Correlated Subquery)와 단짝처럼 붙어 다닙니다.
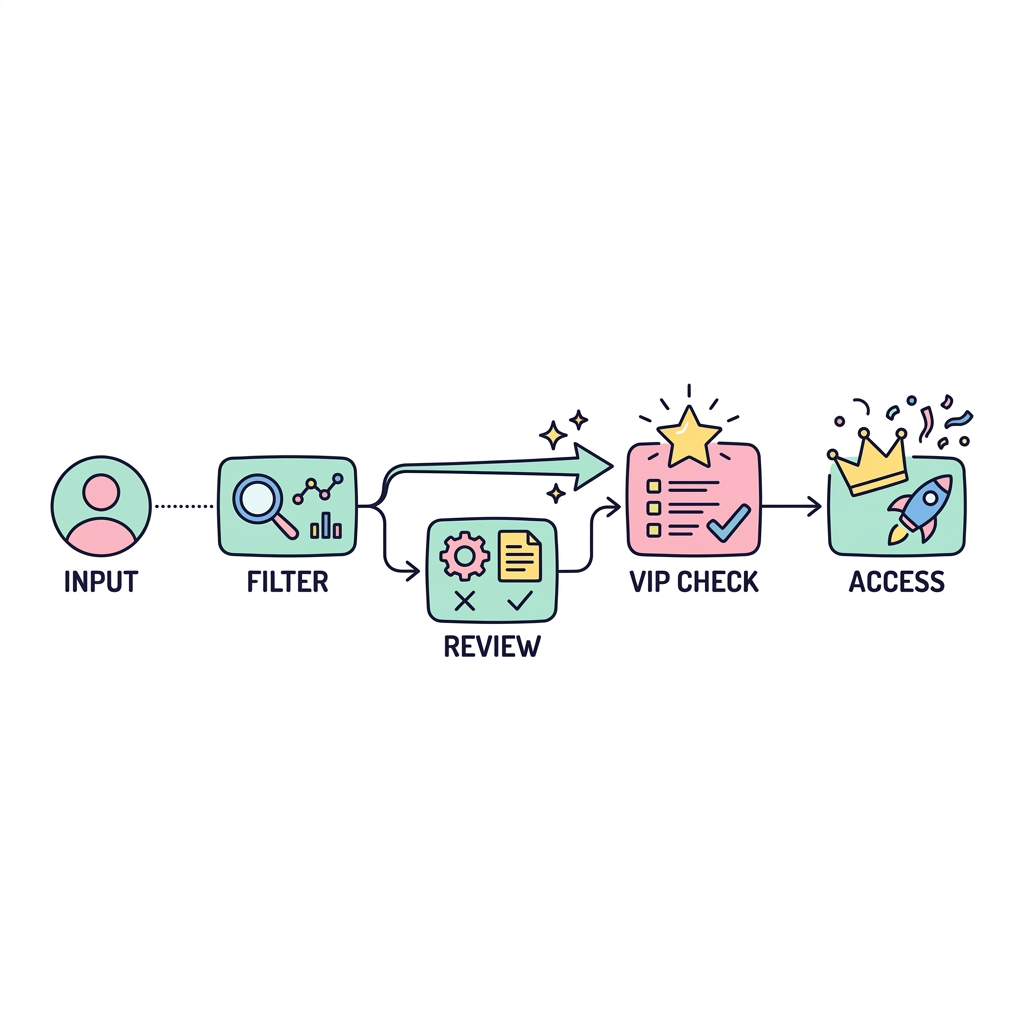
💡 핵심 비유
VIP 명단 확인하기
입장객 리스트 전체를 스캔해서 짐을 다 검사하는 게 아니라, VIP 명단에 이름이 "존재하는지(EXISTS)"만 쓱 보고 통과시키는 패스트트랙과 같습니다.
🧩 원리 이해하기
집합 연산자 (UNION, INTERSECT, EXCEPT)
집합 연산자 (UNION, INTERSECT, EXCEPT)
두 개 이상의 SELECT 쿼리 결과를 수학의 집합(Set)처럼 더하고, 빼고, 공통점만 찾을 수 있습니다. 위아래로 데이터를 합치는 UNION, 교집합만 찾는 INTERSECT, 차집합을 구하는 EXCEPT(오라클은 MINUS)가 있습니다.
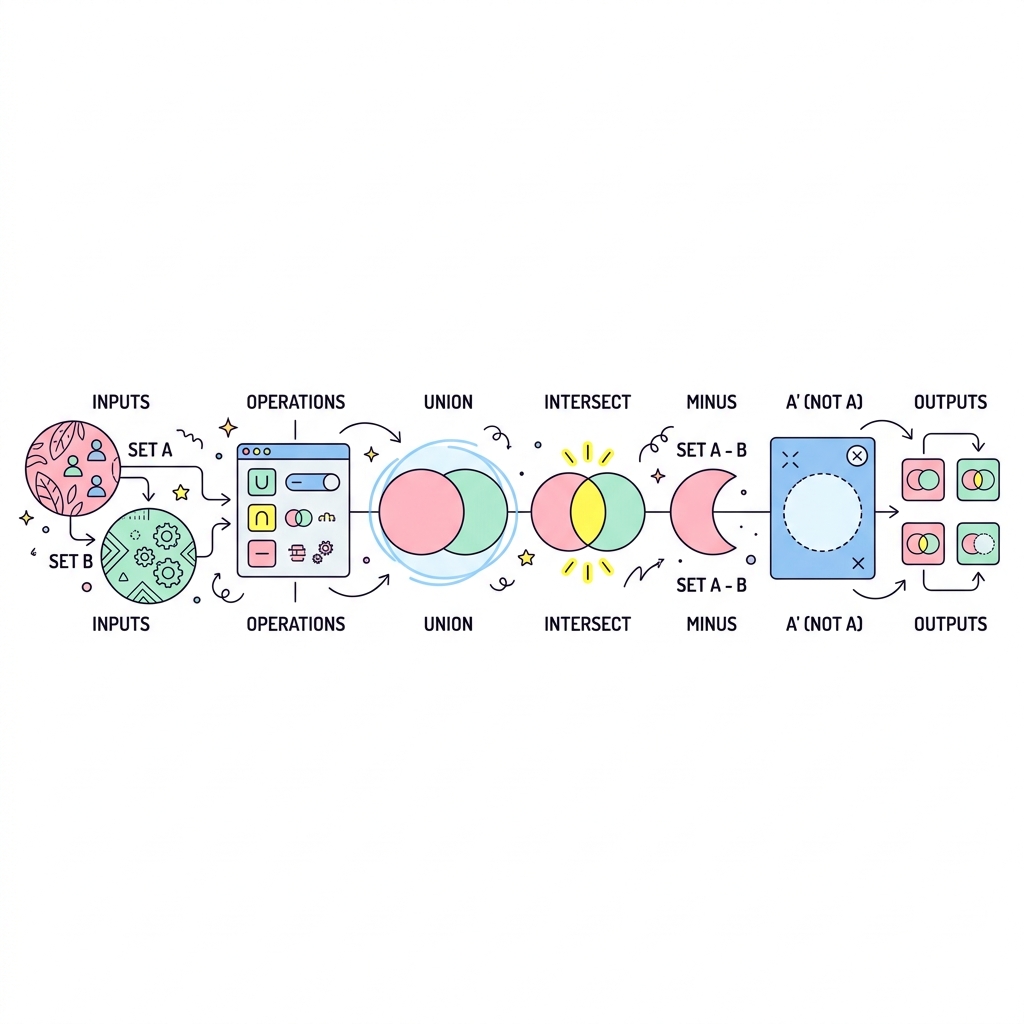
💡 핵심 비유
블록 쌓기와 빼기
A 상자의 레고 블록 결과물과 B 상자의 레고 블록 결과물을 위아래로 길게 합쳐서(UNION) 하나의 거대한 탑을 만드는 것과 같습니다.
🧩 원리 이해하기
데이터 추가하기 (INSERT)
데이터 추가하기 (INSERT)
지금까지 데이터를 조회(SELECT)하는 방법만 배웠다면, 이제는 빈 테이블에 새로운 데이터를 밀어 넣는(생성하는) 방법입니다. INSERT INTO ... VALUES ... 구문을 사용하여 새로운 행(Row)을 추가합니다.

💡 핵심 비유
새 서랍장에 양말 넣기
"옷장(테이블)"의 "1번 서랍(컬럼1), 2번 서랍(컬럼2)"에 "빨간 양말(값1), 파란 양말(값2)"을 각각 제자리에 쏙 밀어넣는 작업입니다.
🧩 원리 이해하기
기존 데이터 수정하기 (UPDATE)
기존 데이터 수정하기 (UPDATE)
이미 저장되어 있는 데이터의 특정 값을 변경(수정)할 때 사용합니다. UPDATE 테이블 SET 컬럼=값 구조를 가집니다. 주의할 점은 WHERE 절을 쓰지 않으면 테이블 전체 데이터가 수정되는 대참사가 발생한다는 것입니다!
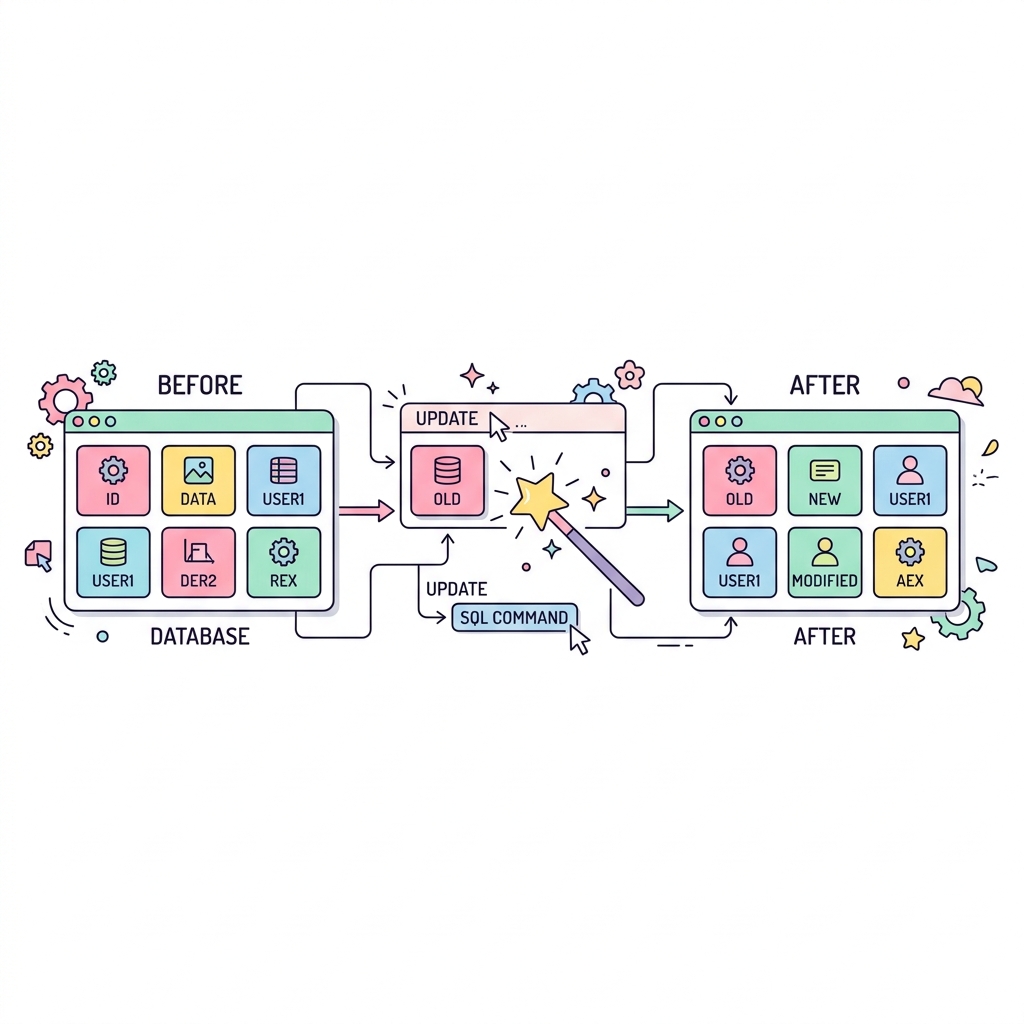
💡 핵심 비유
명찰 바꿔 달기
학생 무리 중에서 "이름표가 '홍길동'인 학생(WHERE)"만 콕 집어서, 새 이름표인 "고길동(SET)"으로 교체해 주는 작업입니다.
🧩 원리 이해하기
데이터 삭제하기 (DELETE)
데이터 삭제하기 (DELETE)
불필요해진 데이터를 데이터베이스에서 완전히 영구적으로 지울 때 사용합니다. UPDATE와 마찬가지로 WHERE 조건을 빼먹으면 테이블의 모든 데이터가 증발(삭제)해 버리니 실무에서 가장 조심해야 하는 명령어 1순위입니다.
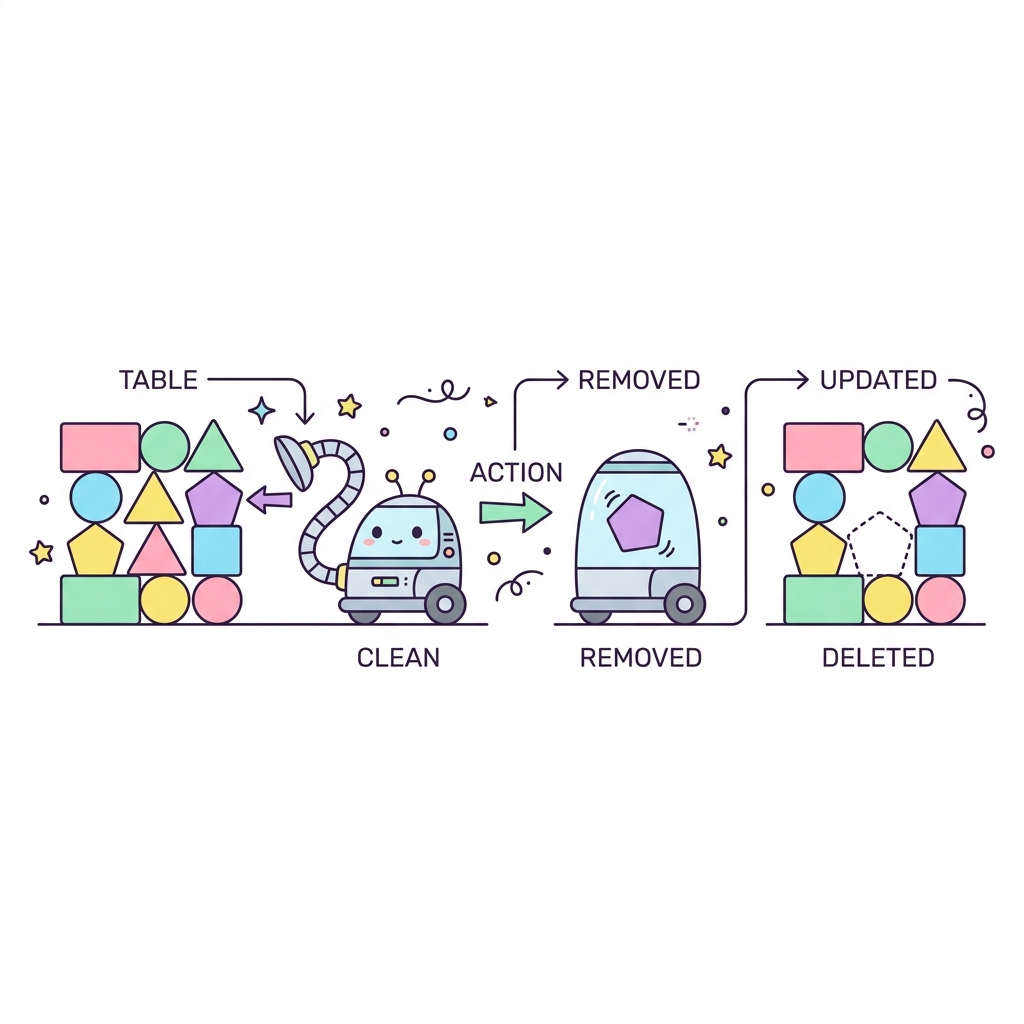
💡 핵심 비유
핀셋으로 불량품 골라내기
수많은 완제품 상자들 중에서 "제조일자가 작년인 상자(WHERE)"들만 핀셋으로 콕 집어서 휴지통에 던져버리는 과정입니다.
🧩 원리 이해하기
트랜잭션의 이해
트랜잭션의 이해
트랜잭션(Transaction)은 "쪼갤 수 없는 하나의 논리적 작업 단위"입니다. 대표적으로 은행의 계좌 이체(A통장 출금 + B통장 입금)가 있습니다. 모든 과정이 완벽히 성공하면 영구 저장(COMMIT)하고, 하나라도 실패하면 작업 전 상태로 완벽히 되돌려야(ROLLBACK) 합니다.

💡 핵심 비유
결제 후 배송 시스템
고객이 돈을 지불하고 물건을 받기 전까지는 "임시 상태"입니다. 물건을 정상적으로 받으면 거래가 확정(COMMIT)되고, 재고가 없으면 돈을 다시 돌려받고 거래가 취소(ROLLBACK)됩니다.
🧩 원리 이해하기
테이블 생성, 수정, 삭제 (DDL)
테이블 생성, 수정, 삭제 (DDL)
데이터 조작(DML: SELECT, INSERT, UPDATE, DELETE)이 뼈대 안의 살을 다루는 것이라면, 데이터 정의(DDL: CREATE, ALTER, DROP)는 데이터가 들어갈 뼈대와 그릇 자체를 만들거나 부수는 작업입니다. DDL은 실행 즉시 자동 COMMIT 되므로 주의해야 합니다.
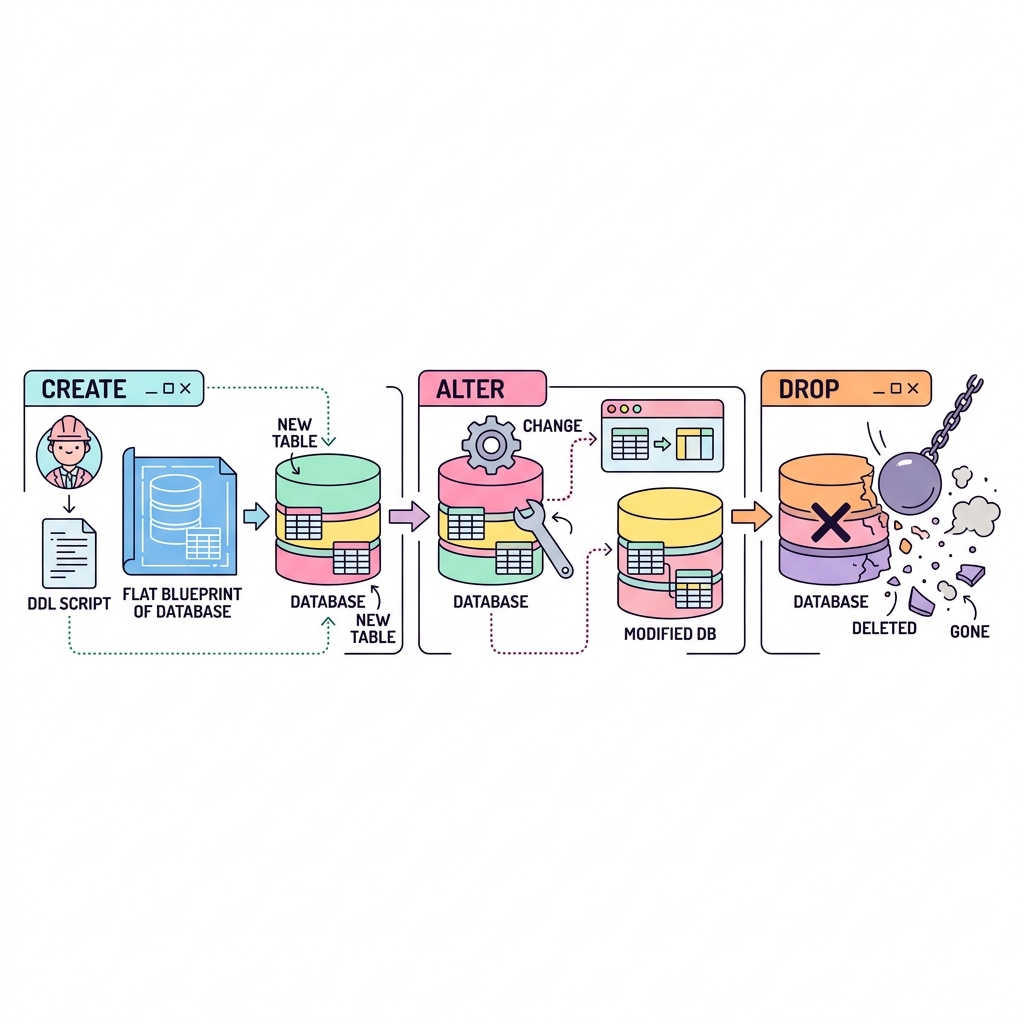
💡 핵심 비유
아파트 설계 및 건축
가구를 배치(DML)하기 전에, 먼저 아파트 건물을 올리고(CREATE), 베란다를 확장(ALTER)하고, 건물을 철거(DROP)하는 가장 크고 근본적인 건축 작업입니다.
🧩 원리 이해하기
무결성과 제약조건
무결성과 제약조건
데이터베이스에 쓰레기 데이터가 들어오지 않도록 막는 문지기 역할입니다. 대표적으로 절대 중복되지 않는 고유 번호인 기본키(Primary Key), 필수 입력인 NOT NULL, 다른 테이블의 존재해야만 하는 값을 참조하는 외래키(Foreign Key) 등이 있습니다.
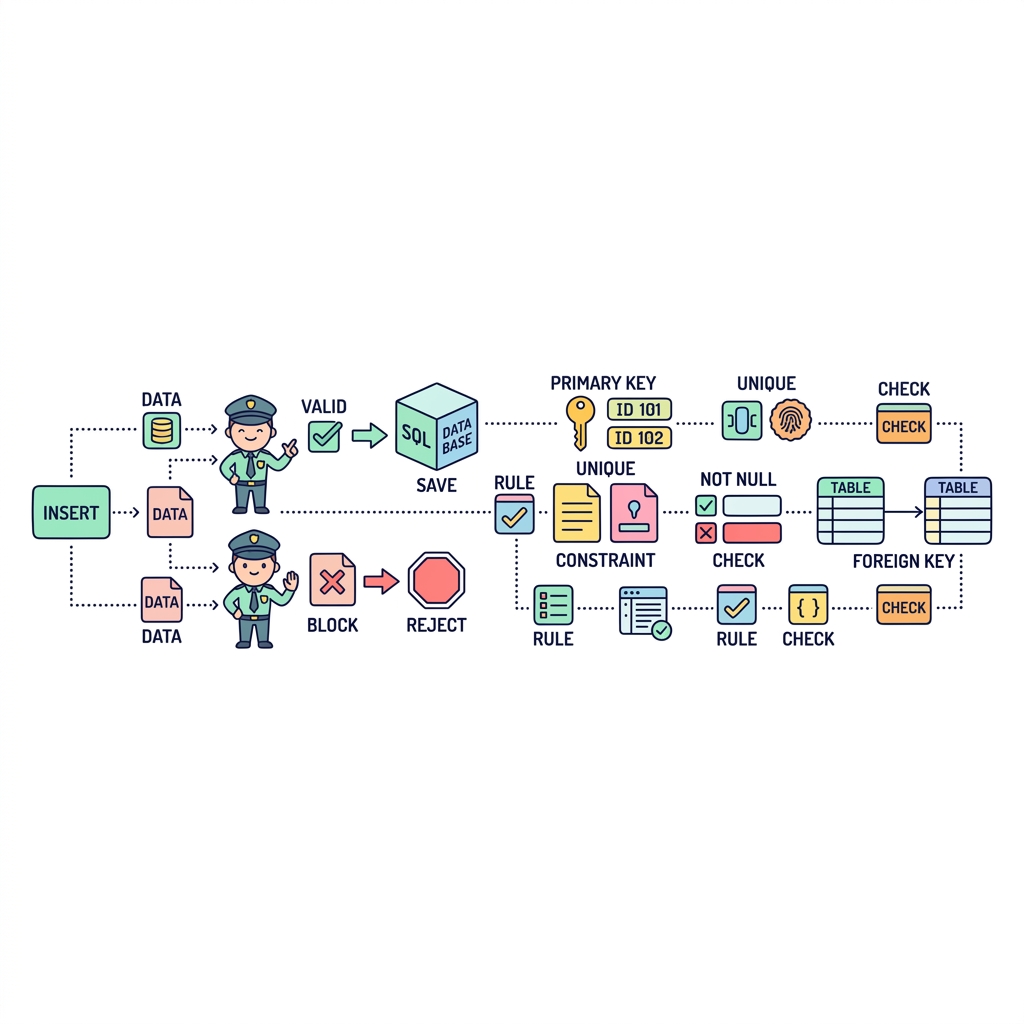
💡 핵심 비유
회원 가입 폼의 빨간 별표(*)
아이디는 중복되면 안 되고(PK), 비밀번호는 무조건 입력해야 하며(NOT NULL), 주민번호는 실제 존재하는 형식이어야(CHECK) 하는 규칙입니다.
🧩 원리 이해하기
뷰(View)의 개념과 활용
뷰(View)의 개념과 활용
뷰(View)는 데이터를 보여주는 가상의 창문(가상 테이블)입니다. 실제 데이터가 저장되는 것은 아니고, 복잡한 쿼리를 하나의 이름표(View)로 저장해두어 재사용하거나, 중요한 특정 컬럼만 보여주어 보안을 지킬 때 사용합니다.
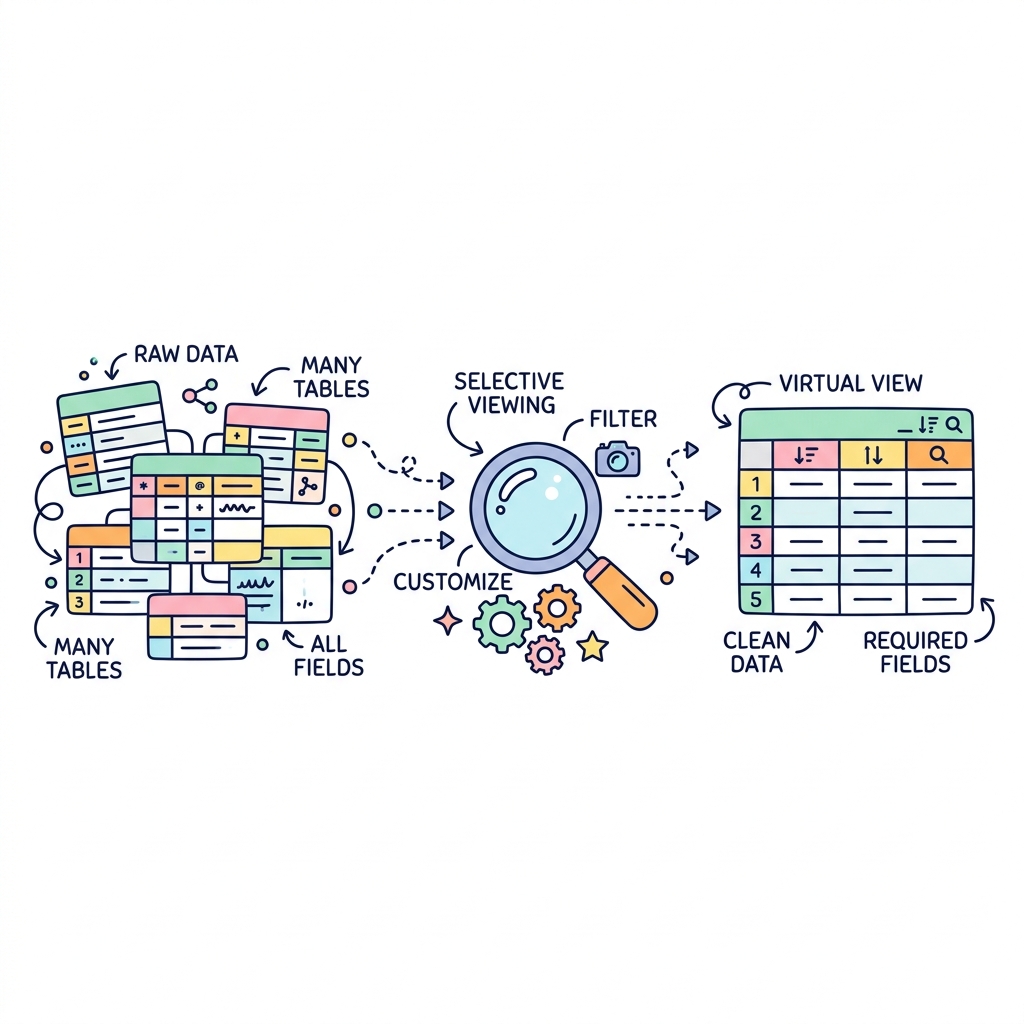
💡 핵심 비유
레스토랑의 유리창
고객(사용자)은 유리창(View)을 통해 예쁘게 플레이팅된 요리만 볼 수 있을 뿐, 지저분한 주방 안쪽(실제 복잡한 테이블) 구조는 알 필요가 없습니다.
🧩 원리 이해하기
공통 테이블 식 (CTE, WITH 구문)
공통 테이블 식 (CTE, WITH 구문)
WITH 구문(CTE, Common Table Expression)은 쿼리 제일 상단에서 임시 가상 테이블을 선언해두고, 아래 메인 쿼리에서 변수처럼 가져다 쓰는 문법입니다. 쿼리가 복잡해질수록 가독성을 극적으로 높여주고 재사용이 가능해 실무에서 몹시 애용됩니다.
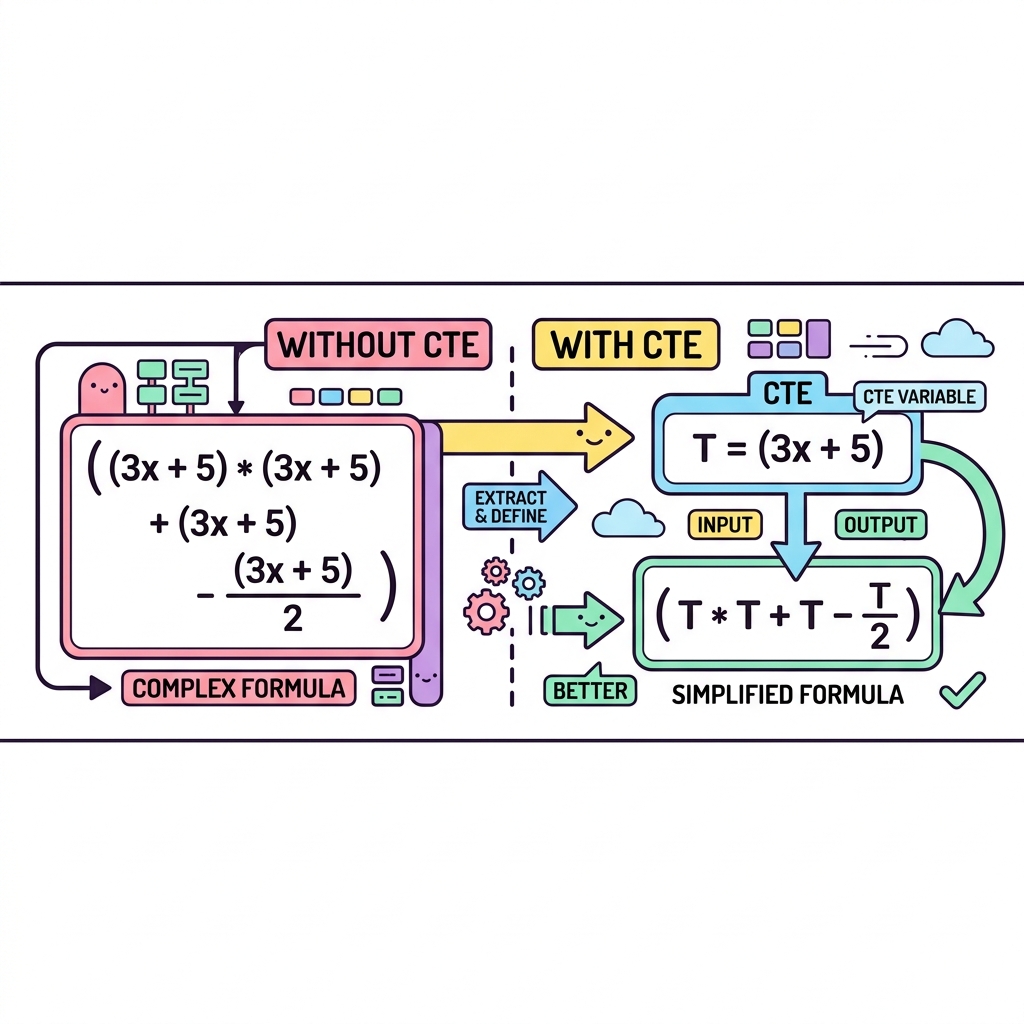
💡 핵심 비유
수학 문제의 치환
복잡하고 긴 수식을 바로 풀지 않고, A = (긴 수식) 이라고 윗부분에 정의해둔 다음, 아랫부분에서 A + B로 간단하게 푸는 것과 완벽히 같습니다.
🧩 원리 이해하기
윈도우 함수 (Window Functions)
윈도우 함수 (Window Functions)
데이터베이스 분석의 꽃입니다. 일반 집계 함수(GROUP BY)는 여러 행을 하나로 뭉개버리지만, 윈도우 함수는 원래의 행(Row) 개수를 그대로 유지하면서, 특정 창문(Window) 범위 내의 집계값이나 순위를 각 행 옆에 나란히 붙여줍니다.
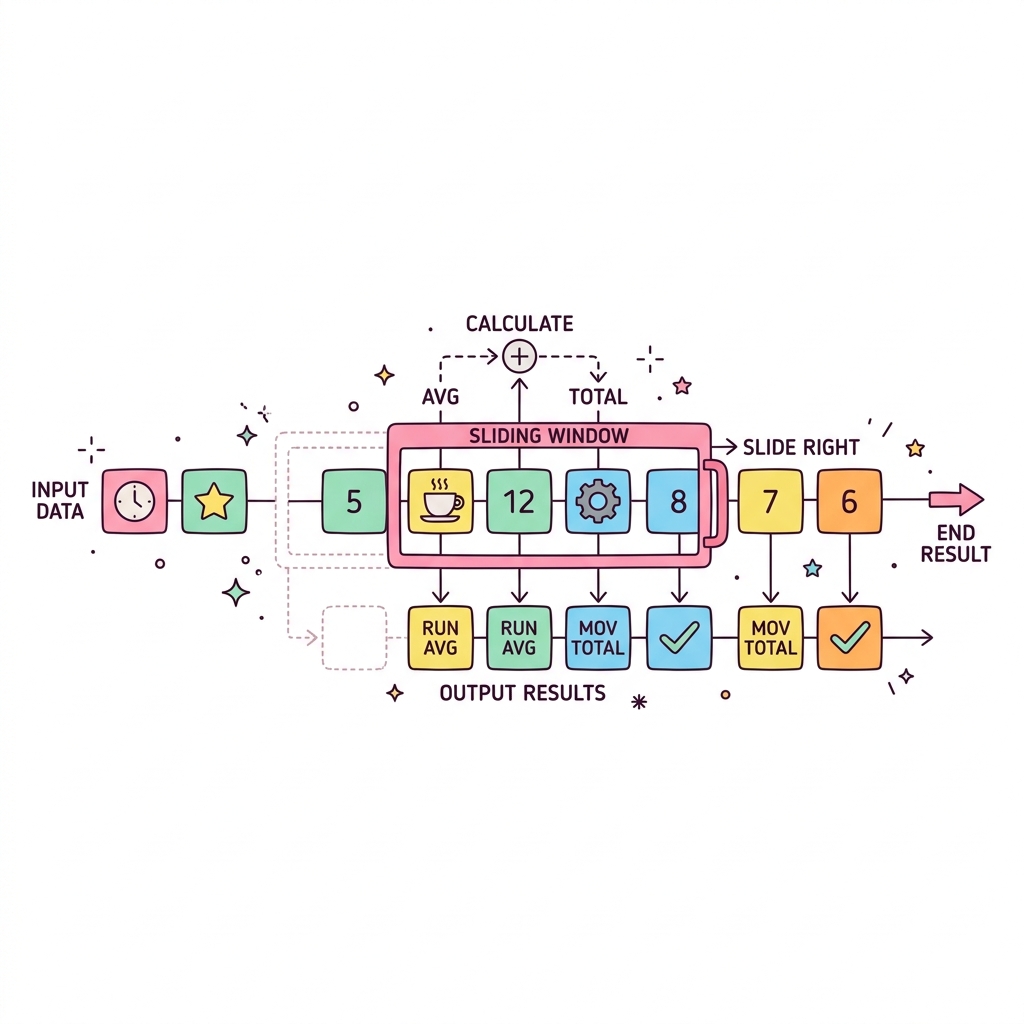
💡 핵심 비유
투명한 슬라이딩 액자
전체 그림(데이터)은 그대로 둔 채, 작은 투명 액자(Window)를 위아래로 움직이면서 "최근 3일간의 누적 합계", "부서 내 나의 급여 순위" 등을 원본 데이터 손실 없이 구하는 기술입니다.
🧩 원리 이해하기
인덱스(Index)의 기본 원리
인덱스(Index)의 기본 원리
인덱스(Index)는 데이터베이스 테이블에 대한 검색 속도를 눈부시게 향상시켜주는 "찾아보기(색인)" 자료구조입니다. 인덱스가 없으면 DB는 데이터를 찾을 때 테이블의 처음부터 끝까지 무식하게 다 뒤져야 하는 풀 테이블 스캔(Full Table Scan)을 하게 됩니다.
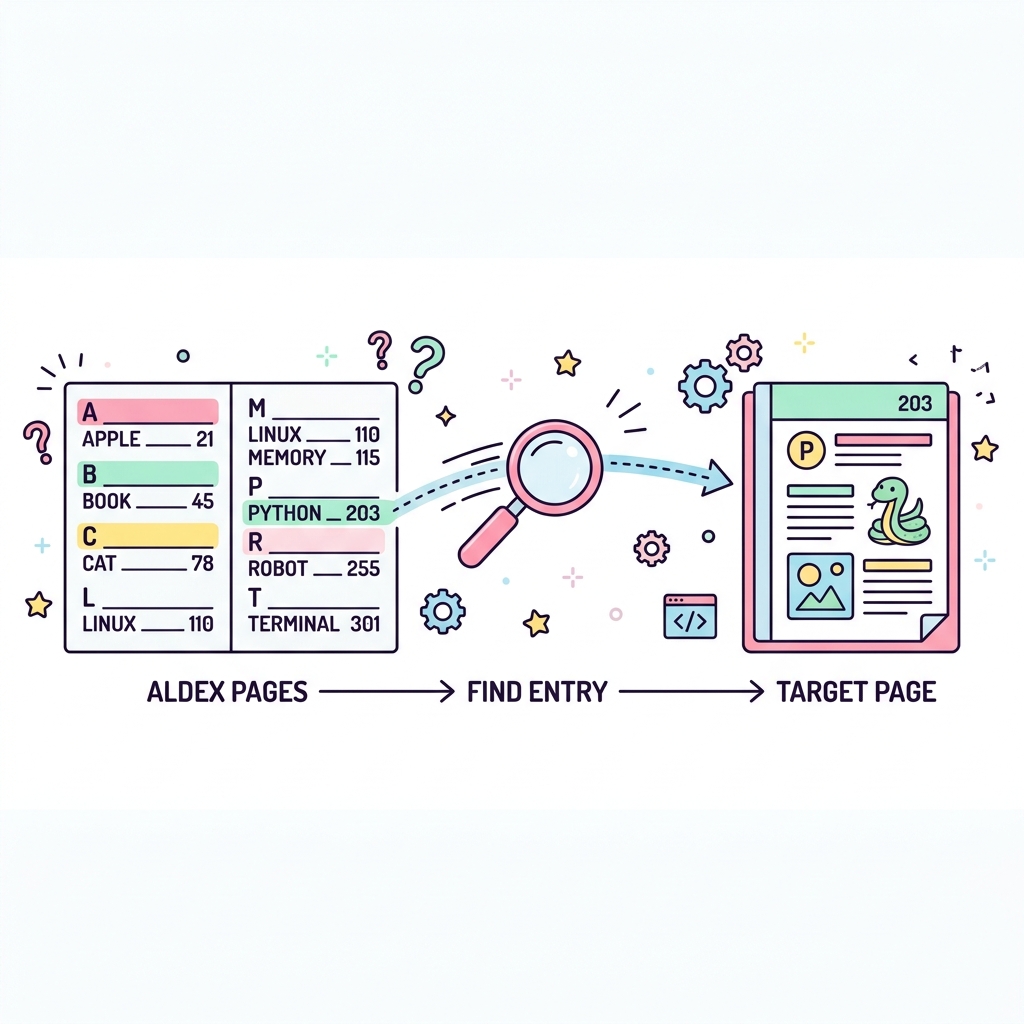
💡 핵심 비유
두꺼운 백과사전의 맨 뒷장 색인
"오라클"이라는 단어를 찾기 위해 백과사전 1000페이지를 한 장씩 넘기는 게 아니라, 맨 뒤의 'ㅇ' 색인에서 "오라클 - 452페이지"를 확인하고 한 번에 452페이지를 펼치는 것과 동일합니다.
🧩 원리 이해하기
데이터베이스와 RDBMS의 이해표준 SQL(ANSI SQL)이란?학습 환경 구축SELECT와 FROMWHERE 절ORDER BYLIMIT / OFFSET다양한 필터링 기법문자열 함수숫자 및 날짜 함수조건 논리 처리집계 함수GROUP BYHAVING관계형 데이터베이스와 JOIN의 필요성내부 조인 (INNER JOIN)외부 조인 (LEFT, RIGHT, FULL OUTER JOIN)교차 조인과 셀프 조인단일행과 다중행 서브쿼리인라인 뷰와 스칼라 서브쿼리연관 서브쿼리와 EXISTS 연산자집합 연산자 (UNION, INTERSECT, EXCEPT)데이터 추가하기 (INSERT)기존 데이터 수정하기 (UPDATE)데이터 삭제하기 (DELETE)트랜잭션의 이해테이블 생성, 수정, 삭제 (DDL)무결성과 제약조건뷰(View)의 개념과 활용공통 테이블 식 (CTE, WITH 구문)윈도우 함수 (Window Functions)인덱스(Index)의 기본 원리