배열과 연결 리스트 (Arrays vs Linked Lists)
자료구조의 양대 산맥: 배열과 연결 리스트
컴퓨터가 데이터를 메모리에 저장하는 가장 기본적인 두 가지 방법입니다. 배열(Array)은 메모리 공간에 빈틈없이 데이터를 나열하며, 연결 리스트(Linked List)는 데이터와 포인터(다음 데이터를 가리키는 주소)를 쌍으로 묶어 메모리 곳곳에 흩어진 채로 자유롭게 이어 나갑니다.
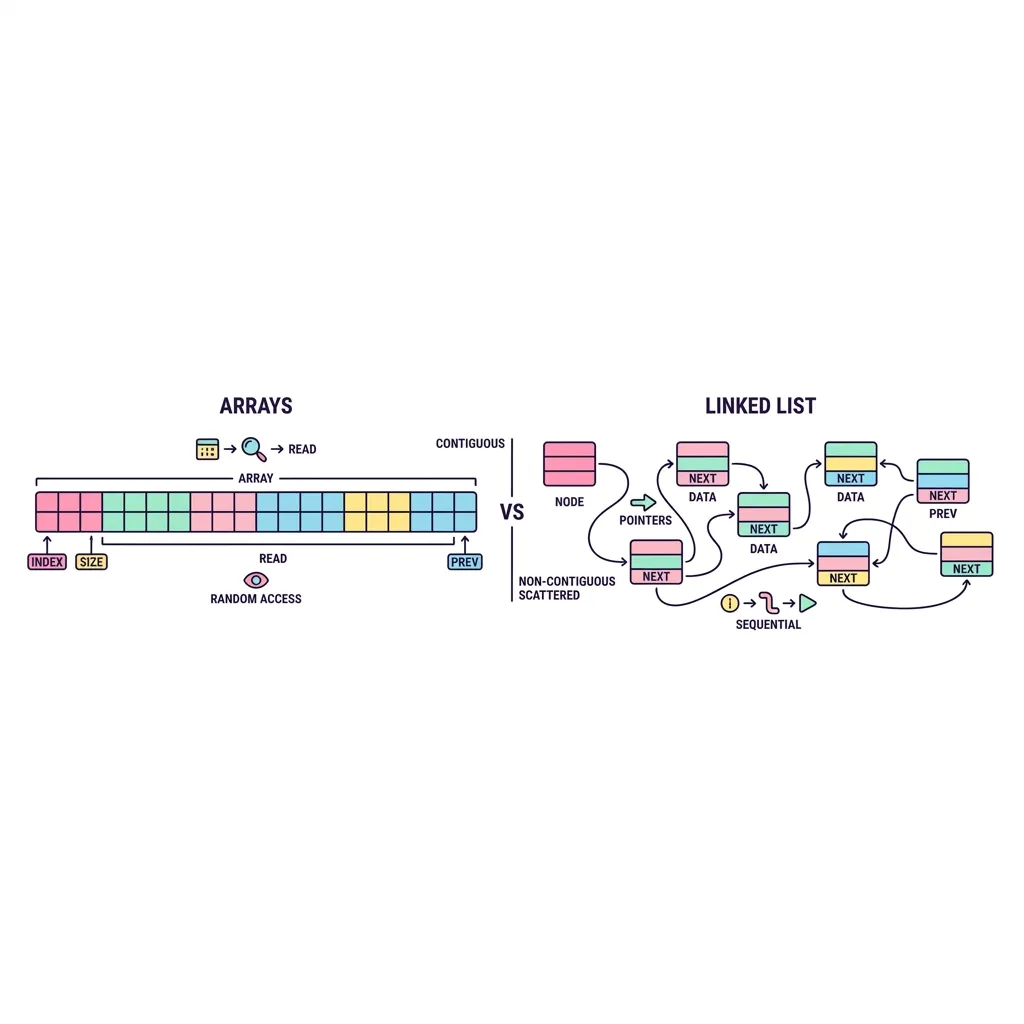
1. 시각적 구조 비교
2. 성능 및 특징 비교 (시간 복잡도)
| 연산 (Operation) | 배열 (Array) | 연결 리스트 (Linked List) | 상세 설명 |
|---|---|---|---|
| 인덱스 접근 (Access) | O(1) 🚀 | O(N) | 배열은 메모리 주소 계산으로 즉시 접근 가능. 반면 연결 리스트는 처음부터 순차적으로 포인터를 따라가야 합니다. |
| 탐색 (Search) | O(N) | O(N) | 특정 '값'을 찾으려면 둘 다 전체를 뒤져야 합니다. (단, 정렬된 배열은 이진 탐색으로 O(log N) 가능) |
| 맨 뒤 삽입/삭제 | O(1) | O(1) (Tail 포인터 시) | 배열의 맨 뒤나, Tail 포인터를 가진 연결 리스트의 맨 뒤 조작은 매우 빠릅니다. |
| 중간 삽입/삭제 | O(N) | O(1) 🚀 (위치 안다면) | 배열은 중간에 끼워넣기 위해 뒤의 모든 요소를 밀어야 하지만, 연결 리스트는 포인터만 '딸깍' 연결해주면 끝납니다. |
💡 실무 지식: 배열의 은밀한 무기, 캐시 지역성(Cache Locality)
이론적으로 중간 삽입/삭제가 빈번하면 연결 리스트가 유리해 보이지만, 실제 물리적인 CPU 환경에서는 다릅니다. 배열은 연속된 메모리를 차지하므로 CPU 캐시(Cache)에 한 번에 왕창 로드되어 엄청나게 빠른 속도를 자랑합니다. (공간 지역성) 반면 흩어져 있는 연결 리스트는 캐시 미스(Cache Miss)가 자주 발생하여 오히려 배열보다 실제 속도가 느린 경우가 많습니다. 현대 프로그래밍 언어들은 대부분 배열(가변 배열)을 기본으로 사용합니다.
// 📂 LinkedList.js (JavaScript)
// 자바스크립트 클래스를 활용한 단순 연결 리스트 구현
class Node {
constructor(data) {
this.data = data;
this.next = null; // 다음 노드를 가리키는 포인터
}
}
class LinkedList {
constructor() {
this.head = null; // 리스트의 시작점
}
append(data) {
const newNode = new Node(data);
if (!this.head) {
this.head = newNode;
return;
}
let current = this.head;
while (current.next) {
current = current.next;
}
current.next = newNode;
}
printList() {
let current = this.head;
const result = [];
while (current) {
result.push(current.data);
current = current.next;
}
console.log(result.join(" -> "));
}
}
// 📂 main.js (사용 예시)
// 1. 배열(Array) 사용
const arr = [10, 20, 30];
arr.push(40);
console.log("Array:", arr);
// 2. 연결 리스트(LinkedList) 사용
const list = new LinkedList();
list.append(10);
list.append(20);
list.append(30);
list.append(40);
process.stdout.write("LinkedList: ");
list.printList();스택과 큐 (Stack & Queue)
스택(Stack)과 큐(Queue)
배열과 연결 리스트가 데이터를 '저장하는 방식'에 대한 구조라면, 스택과 큐는 데이터를 '넣고 빼는 순서(Rule)'에 대한 논리적 자료구조입니다. 스택은 프링글스 과자통처럼 가장 늦게 들어간 데이터가 가장 먼저 나오는 LIFO(Last-In-First-Out) 방식이며, 큐는 톨게이트 줄서기처럼 먼저 온 데이터가 먼저 처리되는 FIFO(First-In-First-Out) 방식입니다.
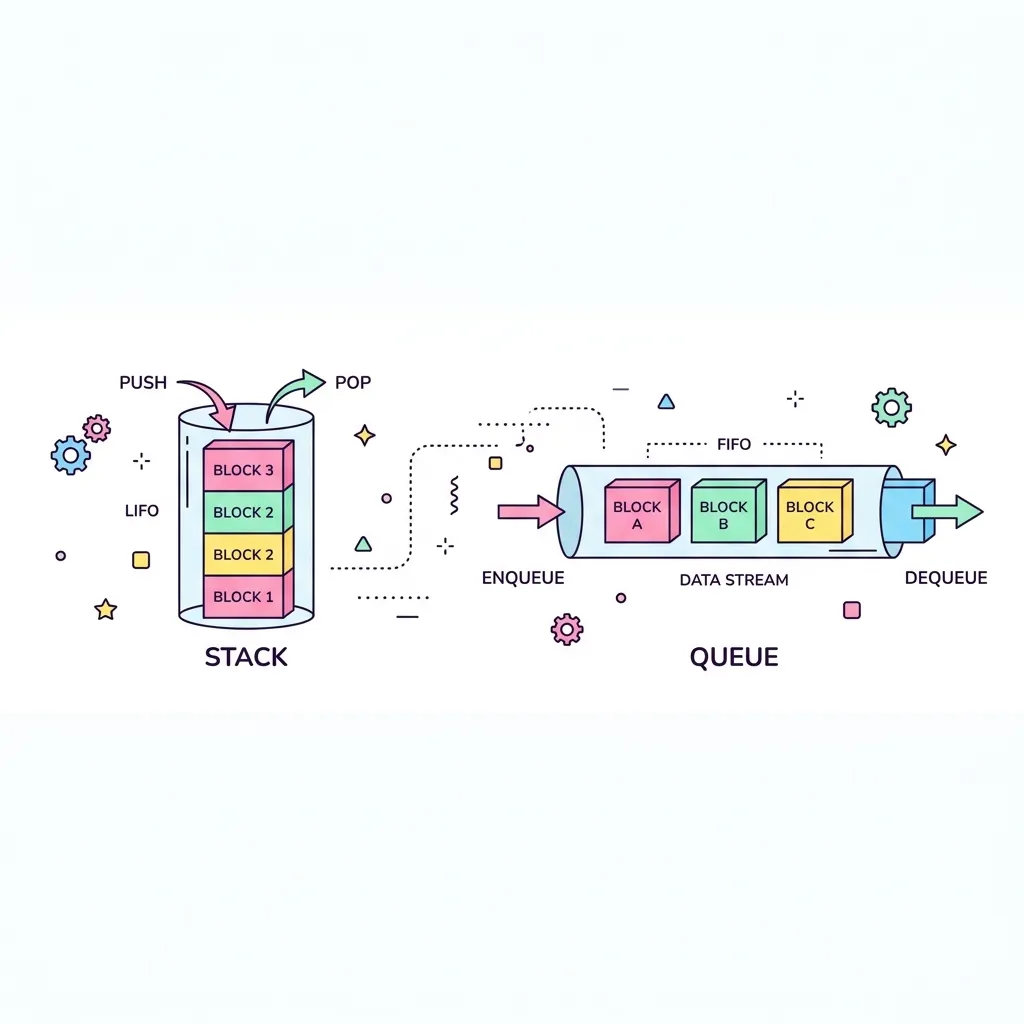
1. 구조 및 동작 원리 (LIFO vs FIFO)
2. 성능 및 특징 요약
| 특징 | 스택 (Stack) | 큐 (Queue) |
|---|---|---|
| 처리 규칙 | LIFO (Last-In-First-Out) | FIFO (First-In-First-Out) |
| 데이터 추가 연산 | Push - 탑(Top) 위치에 추가 | Enqueue - 꼬리(Rear) 위치에 추가 |
| 데이터 추출 연산 | Pop - 탑(Top) 위치에서 제거 및 반환 | Dequeue - 머리(Front) 위치에서 제거 및 반환 |
| 시간 복잡도 (삽입/삭제) | O(1) | O(1) |
💡 실무 지식: 어디에 쓰이나요?
스택(Stack)은 주로 '최근의 상태를 기억하고 되돌릴 때' 사용합니다. 대표적으로 에디터의 '실행 취소(Ctrl+Z)', 웹 브라우저의 '뒤로 가기', 프로그래밍 언어의 함수 호출 스택(Call Stack) 구현에 쓰입니다.
큐(Queue)는 '순서대로 일을 처리해야 할 때' 사용합니다. 인쇄 작업 대기열, 은행 번호표 처리 시스템, 식당의 주문 시스템, 그리고 비동기 데이터 통신에서의 메시지 큐(Message Queue - Kafka, RabbitMQ) 등 순서 보장이 필수인 곳에 쓰입니다.
// 📂 DataStructures.js (JavaScript)
// 자바스크립트는 배열(Array) 자체에 스택과 큐를 위한 내장 메서드가 모두 존재합니다.
// 1. Stack (LIFO)
class Stack {
constructor() {
this.items = [];
}
push(element) {
this.items.push(element); // 배열의 맨 끝에 추가 (O(1))
}
pop() {
return this.items.pop(); // 배열의 맨 끝에서 제거 (O(1))
}
peek() {
return this.items[this.items.length - 1];
}
}
// 2. Queue (FIFO)
class Queue {
constructor() {
this.items = [];
}
enqueue(element) {
this.items.push(element); // 배열의 맨 끝에 추가 (O(1))
}
dequeue() {
// shift()는 O(N)의 시간이 걸리므로 실제로는 연결리스트 기반 큐가 더 효율적입니다.
return this.items.shift(); // 배열의 맨 앞(0번 인덱스)에서 제거
}
}
// 실행 예시
const stack = new Stack();
stack.push("A");
stack.push("B");
console.log("Stack Pop:", stack.pop()); // B 출력
const queue = new Queue();
queue.enqueue("1번 손님");
queue.enqueue("2번 손님");
console.log("Queue Dequeue:", queue.dequeue()); // 1번 손님 출력해시 테이블 (Hash Table)
해시 테이블 (Hash Table)
데이터를 순차적으로 뒤지며 찾는 O(N)의 고통에서 벗어나게 해주는 마법의 상자입니다. Key-Value(키-값) 쌍으로 데이터를 저장하며, 입력된 'Key'를 신비한 해시 함수(Hash Function)에 통과시키면 데이터를 저장할 '고유한 위치(배열 인덱스)'가 즉시 튀어나옵니다. 이 덕분에 데이터가 수백만 개라도 단 한 번의 접근(O(1))만에 원하는 데이터를 찰나에 찾아낼 수 있습니다.
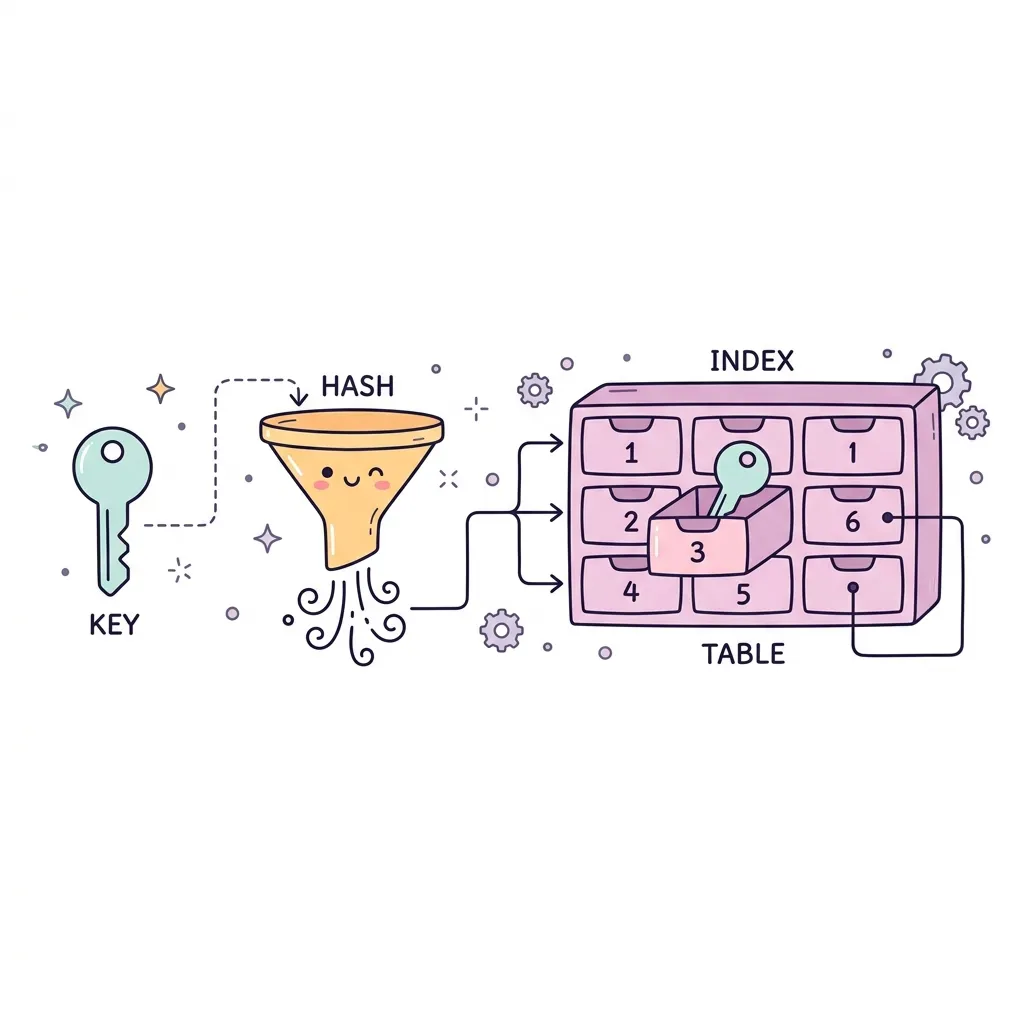
1. 구조 및 해시 충돌(Collision) 해결법
2. 성능 및 특징 요약
| 연산 (Operation) | 평균 시간 복잡도 | 최악의 경우 (Worst Case) | 비고 |
|---|---|---|---|
| 탐색 (Search) | O(1) 🚀 | O(N) | 충돌이 발생하지 않으면 단번에 찾습니다. 모든 데이터가 하나의 슬롯에 충돌(Collision)하면 연결 리스트를 순회해야 하므로 O(N)이 됩니다. |
| 삽입 (Insert) | O(1) 🚀 | O(N) | 마찬가지로 배열의 인덱스에 접근하여 즉시 할당합니다. |
| 삭제 (Delete) | O(1) 🚀 | O(N) | Key를 해시 변환하여 인덱스를 찾고 바로 삭제합니다. |
💡 실무 지식: 해시 충돌(Collision)과 Redis
서로 다른 Key가 우연히 같은 배열 인덱스를 가리키는 현상을 해시 충돌(Collision)이라 합니다. 이를 해결하기 위해 같은 칸에 값이 겹치면 연결 리스트로 줄줄이 달아버리는 체이닝(Chaining) 방식과, 빈 칸을 찾아 옆으로 이동하는 개방 주소법(Open Addressing) 방식이 쓰입니다.
실무에서 해시 테이블은 정말 지겹게 사용됩니다. 데이터베이스에서 빠른 조회를 위한 해시 인덱스, JSON 데이터를 다루는 딕셔너리 객체, 그리고 무엇보다 Redis, Memcached 같은 인메모리 캐시 시스템의 핵심 엔진이 바로 이 해시 테이블 메커니즘입니다!
// 📂 HashTable.js (JavaScript)
// 자바스크립트의 객체(Object)와 Map은 내부적으로 해시 테이블을 사용합니다.
// 여기서는 원리를 이해하기 위해 배열을 이용해 직접 해시 테이블을 구현해 봅니다.
class HashTable {
constructor(size = 50) {
this.buckets = new Array(size);
this.size = size;
}
// 간단한 문자열 해시 함수
_hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % this.size;
}
// 체이닝(Chaining) 기법을 사용한 데이터 삽입
set(key, value) {
const index = this._hash(key);
if (!this.buckets[index]) {
this.buckets[index] = [];
}
this.buckets[index].push([key, value]);
}
// Key를 통해 O(1)에 가까운 속도로 Value 탐색
get(key) {
const index = this._hash(key);
const bucket = this.buckets[index];
if (bucket) {
for (let i = 0; i < bucket.length; i++) {
if (bucket[i][0] === key) {
return bucket[i][1];
}
}
}
return undefined;
}
}
// 실행 예시
const myHash = new HashTable();
myHash.set("name", "Minstudio");
myHash.set("age", 25);
console.log("Name:", myHash.get("name")); // Minstudio 출력
// 💡 실무에서는 자바스크립트 내장 Map을 쓰는 것이 가장 성능이 좋습니다.
const map = new Map();
map.set("name", "Minstudio");
console.log("Map Output:", map.get("name"));트리와 이진 탐색 트리 (Tree & BST)
트리(Tree)와 이진 탐색 트리(BST)
배열과 연결 리스트가 데이터를 일렬로 늘어놓는 선형 구조라면, 트리(Tree)는 나무의 뿌리(Root)에서 가지가 뻗어나가는 형태의 계층적(Hierarchical) 비선형 구조입니다. 특히 이진 탐색 트리(Binary Search Tree, BST)는 부모 노드를 기준으로 "작은 값은 왼쪽, 큰 값은 오른쪽"이라는 엄격한 규칙을 적용하여, 데이터를 탐색할 때마다 탐색 대상을 절반씩 줄여나가는 O(log N)의 기적적인 속도를 자랑합니다.
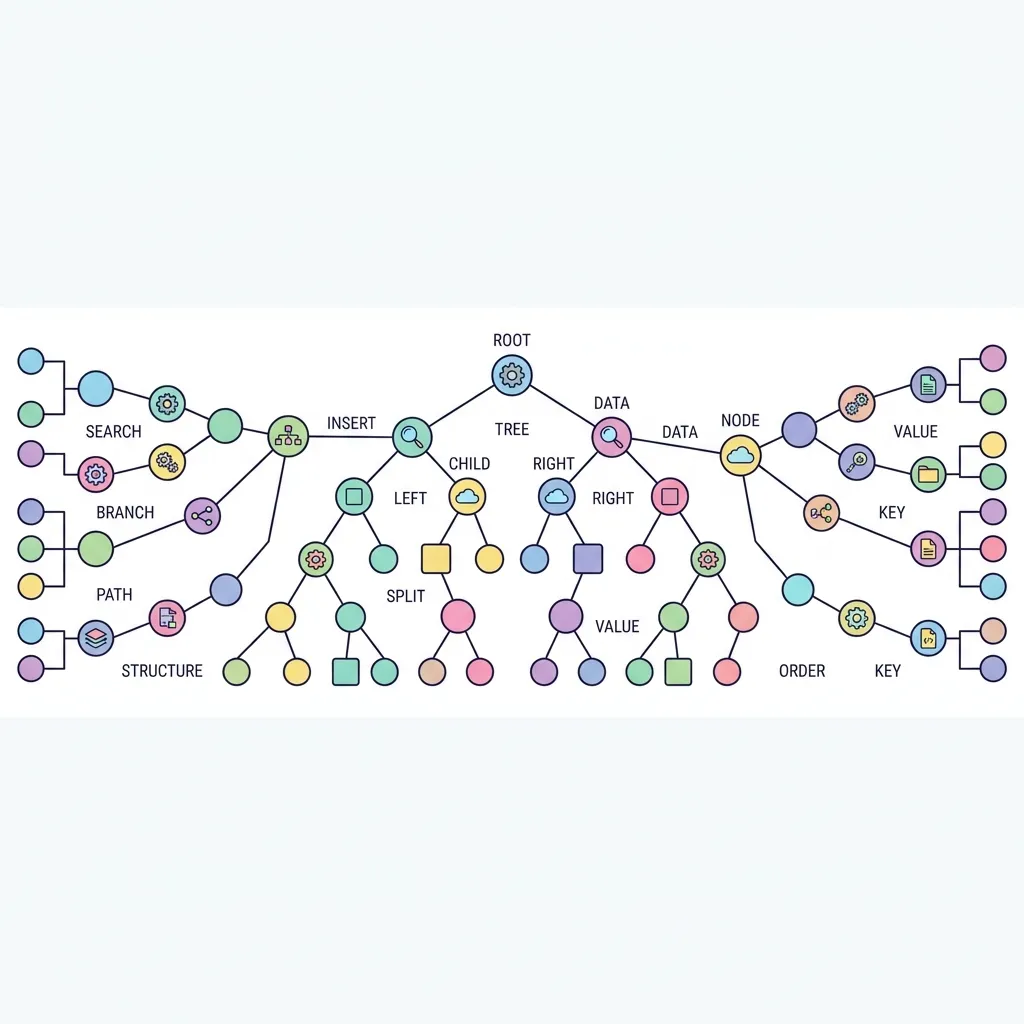
1. 이진 탐색 트리(BST)의 규칙과 탐색 시뮬레이션
2. 성능 및 특징 요약
| 연산 (Operation) | 평균 시간 복잡도 (균형 트리) | 최악의 경우 (편향 트리) |
|---|---|---|
| 탐색 (Search) | O(log N) | O(N) |
| 삽입 (Insert) | O(log N) | O(N) |
| 삭제 (Delete) | O(log N) | O(N) |
💡 실무 지식: 밸런스가 무너진 트리의 위험성 (편향 트리)
만약 트리 모델에 [10, 20, 30, 40, 50] 처럼 이미 정렬된 데이터를 순서대로 삽입하면 어떻게 될까요? 계속 오른쪽 가지로만 뻗어나가며 결국 연결 리스트와 다를 바 없는 일자형(편향) 트리가 되어버립니다. 이 경우 탐색 시간이 O(N)으로 극악의 성능 저하를 일으킵니다.
따라서 실무 시스템(특히 RDBMS의 데이터베이스 인덱스)에서는 노드를 추가/삭제할 때마다 스스로 밸런스를 조정하여 양쪽 깊이를 엇비슷하게 맞추는 AVL 트리, Red-Black 트리, B-Tree 등의 진화된 균형 탐색 트리 구조를 기본 탑재하고 있습니다.
// 📂 BST.js (JavaScript)
// 클래스를 활용하여 노드(Node)와 이진 탐색 트리(BST)를 구현합니다.
class Node {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor() {
this.root = null;
}
// 데이터 삽입
insert(value) {
const newNode = new Node(value);
if (this.root === null) {
this.root = newNode;
return this;
}
let current = this.root;
while (true) {
if (value === current.value) return undefined; // 중복 허용 안함
if (value < current.value) { // 작으면 왼쪽으로
if (current.left === null) {
current.left = newNode;
return this;
}
current = current.left;
} else { // 크면 오른쪽으로
if (current.right === null) {
current.right = newNode;
return this;
}
current = current.right;
}
}
}
// 데이터 탐색 (O(log N))
find(value) {
if (this.root === null) return false;
let current = this.root;
let found = false;
while (current && !found) {
if (value < current.value) {
current = current.left;
} else if (value > current.value) {
current = current.right;
} else {
found = true; // 찾음!
}
}
return found ? current : false;
}
}
// 실행 예시
const tree = new BinarySearchTree();
tree.insert(10);
tree.insert(5);
tree.insert(15);
tree.insert(2);
console.log("트리에서 15 탐색:", tree.find(15)); // Node { value: 15, left: null, right: null }
console.log("트리에서 99 탐색:", tree.find(99)); // false힙과 우선순위 큐 (Heap & Priority Queue)
힙(Heap)과 우선순위 큐(Priority Queue)
큐(Queue)가 식당에서 줄을 선 순서대로(First In, First Out) 들어가는 구조라면, 우선순위 큐(Priority Queue)는 응급실처럼 '가장 위급한 환자(가장 우선순위가 높은 데이터)'가 먼저 들어가는 구조입니다.
이러한 우선순위 큐를 가장 빠르고 효율적으로 구현하기 위해 사용하는 마법의 자료구조가 바로 힙(Heap)입니다. 힙은 완전 이진 트리(Complete Binary Tree)의 형태를 가지며, 부모가 자식보다 항상 크거나(Max Heap), 항상 작은(Min Heap) 상태를 유지합니다.
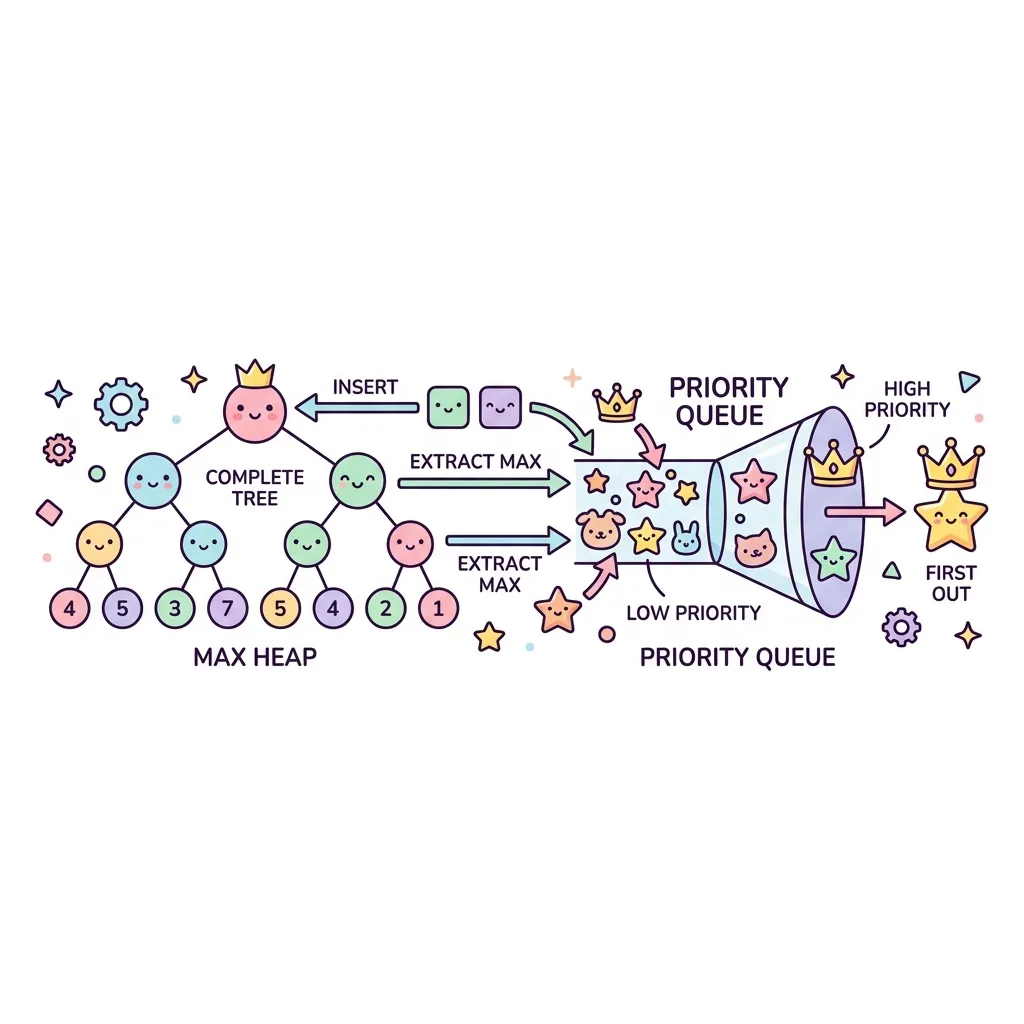
1. 최대 힙(Max Heap) 동작 원리
2. 배열을 통한 힙 구현 (인덱스 공식)
힙은 트리 형태를 띠고 있지만, 실제 메모리 상에서는 배열(Array)로 저장됩니다. 완전 이진 트리의 특성 덕분에 빈 공간 없이 차례대로 배열에 들어맞기 때문입니다.
만약 현재 노드의 인덱스가 i 라면, 부모와 자식 노드의 인덱스는 다음과 같은 마법의 공식으로 즉시 알아낼 수 있습니다.
- 부모 노드 인덱스 = Math.floor((i - 1) / 2)
- 왼쪽 자식 인덱스 = 2 * i + 1
- 오른쪽 자식 인덱스 = 2 * i + 2
💡 실무 지식: 힙은 언제 쓰이나요?
단순히 데이터 전체를 정렬(Sort)해야 한다면 퀵 정렬이나 병합 정렬을 씁니다. 하지만 수많은 데이터 중 "가장 큰 값" 또는 "가장 작은 값" 몇 개만 반복적으로 빠르게 꺼내야 할 때 힙은 빛을 발합니다.
예를 들어 운영체제의 프로세스 스케줄링(가장 중요한 작업 먼저 처리), 다익스트라(Dijkstra) 최단 경로 알고리즘, 슬랙(Slack)이나 카카오톡의 메시지 큐 등에서 핵심적인 엔진 역할을 수행합니다.
// 📂 MaxHeap.js (JavaScript)
// 자바스크립트는 기본적으로 힙이나 우선순위 큐 내장 객체가 없으므로, 배열을 이용해 직접 구현합니다.
class MaxHeap {
constructor() {
this.heap = [];
}
// 부모, 왼쪽 자식, 오른쪽 자식 인덱스 계산 공식
parent(i) { return Math.floor((i - 1) / 2); }
leftChild(i) { return 2 * i + 1; }
rightChild(i) { return 2 * i + 2; }
swap(i, j) {
[this.heap[i], this.heap[j]] = [this.heap[j], this.heap[i]];
}
// 🌟 데이터 삽입 (O(log N))
push(value) {
this.heap.push(value);
this.heapifyUp(this.heap.length - 1);
}
// 삽입 후 부모와 비교하며 위로 끌어올림 (Max Heap 성질 복구)
heapifyUp(i) {
while (i > 0 && this.heap[this.parent(i)] < this.heap[i]) {
this.swap(this.parent(i), i);
i = this.parent(i);
}
}
// 🌟 최댓값 추출 (O(log N))
pop() {
if (this.heap.length === 0) return null;
if (this.heap.length === 1) return this.heap.pop();
const max = this.heap[0]; // 루트 노드(최댓값) 저장
this.heap[0] = this.heap.pop(); // 맨 끝 노드를 루트로 올림
this.heapifyDown(0); // 다시 아래로 내리며 정렬
return max;
}
// 루트에서부터 자식과 비교하며 아래로 내려감
heapifyDown(i) {
let maxIndex = i;
const left = this.leftChild(i);
const right = this.rightChild(i);
if (left < this.heap.length && this.heap[left] > this.heap[maxIndex]) {
maxIndex = left;
}
if (right < this.heap.length && this.heap[right] > this.heap[maxIndex]) {
maxIndex = right;
}
if (maxIndex !== i) {
this.swap(i, maxIndex);
this.heapifyDown(maxIndex);
}
}
}
// 실행 예시
const maxHeap = new MaxHeap();
maxHeap.push(15);
maxHeap.push(40);
maxHeap.push(10);
maxHeap.push(50);
console.log("최댓값 추출:", maxHeap.pop()); // 50 출력 (가장 큰 값이 먼저 나옴)
console.log("다음 최댓값 추출:", maxHeap.pop()); // 40 출력그래프 (Graph)
그래프 (Graph)
지금까지 배운 모든 자료구조(배열, 연결 리스트, 큐, 트리 등)가 데이터의 "상하/전후" 관계를 나타냈다면, 그래프(Graph)는 세상의 모든 "복잡한 네트워크(거미줄)" 관계를 표현할 수 있는 끝판왕 비선형 자료구조입니다.
우리가 매일 사용하는 지도 앱(카카오맵, 네비게이션)의 최단 경로 탐색, 인스타그램/페이스북의 친구 추천 시스템, 심지어 인공지능 신경망(Neural Network)까지 모두 그래프 자료구조를 기반으로 동작합니다.
1. 그래프의 구성 요소와 네트워크 모델
2. 인접 행렬(Matrix) vs 인접 리스트(List)
| 비교 항목 | 인접 행렬 (Adjacency Matrix) | 인접 리스트 (Adjacency List) |
|---|---|---|
| 구현 방식 | 2차원 배열(N x N)로 연결 여부를 0과 1로 표시 |
각 정점마다 배열/리스트를 두어 연결된 노드만 저장 |
| 메모리 공간 | O(V²) (연결되지 않은 곳도 모두 저장하여 낭비 심함) |
O(V + E) (실제 연결된 선의 개수만큼만 메모리 차지) |
| 조회 속도 | 두 노드가 연결되었는지 확인 속도 매우 빠름 O(1) |
해당 노드의 리스트를 순회해야 하므로 O(간선 수) |
| 주 사용처 | 노드 개수가 적고 간선이 매우 빽빽한(Dense) 그래프 | 실무 대부분 (수백만 유저 SNS 등 듬성듬성한 Sparse 그래프) |
💡 실무 지식: 그래프 탐색의 양대 산맥, BFS와 DFS
수많은 데이터가 복잡하게 얽힌 그래프에서 목적지를 찾는 두 가지 핵심 알고리즘이 있습니다.
1. BFS (너비 우선 탐색) : "나와 가까운 1촌부터 전부 스캔하고, 그 다음 2촌을 스캔하는 방식". 주로 최단 경로(네비게이션)를 찾을 때 사용하며 큐(Queue)를 사용해 구현합니다.
2. DFS (깊이 우선 탐색) : "한 우물만 끝까지 파고들어 갔다가, 막히면 되돌아오는 방식". 주로 모든 경로를 다 탐색(미로 찾기)해야 할 때 사용하며 재귀 함수나 스택(Stack)을 사용해 구현합니다.
// 📂 Graph.js (JavaScript)
// 그래프는 보통 인접 리스트(Adjacency List) 방식으로 구현합니다. (메모리 절약)
class Graph {
constructor() {
this.adjacencyList = {};
}
// 정점(Vertex) 추가
addVertex(vertex) {
if (!this.adjacencyList[vertex]) {
this.adjacencyList[vertex] = [];
}
}
// 간선(Edge) 추가 (무방향 그래프 기준)
addEdge(v1, v2) {
this.adjacencyList[v1].push(v2);
this.adjacencyList[v2].push(v1); // 양방향 연결
}
// 간선(Edge) 제거
removeEdge(v1, v2) {
this.adjacencyList[v1] = this.adjacencyList[v1].filter(v => v !== v2);
this.adjacencyList[v2] = this.adjacencyList[v2].filter(v => v !== v1);
}
// 정점(Vertex) 제거
removeVertex(vertex) {
while (this.adjacencyList[vertex].length) {
const adjacentVertex = this.adjacencyList[vertex].pop();
this.removeEdge(vertex, adjacentVertex);
}
delete this.adjacencyList[vertex];
}
}
// 🌐 소셜 네트워크(SNS) 친구 관계 그래프 생성
const sns = new Graph();
sns.addVertex("Alice");
sns.addVertex("Bob");
sns.addVertex("Charlie");
sns.addEdge("Alice", "Bob"); // 앨리스와 밥은 친구!
sns.addEdge("Bob", "Charlie"); // 밥과 찰리는 친구!
console.log(sns.adjacencyList);
/*
출력 결과:
{
Alice: [ 'Bob' ],
Bob: [ 'Alice', 'Charlie' ],
Charlie: [ 'Bob' ]
}
*/트라이 (Trie)
트라이 (Trie / Prefix Tree)
구글이나 네이버 검색창에 '자료'라고만 쳐도 '자료구조', '자료구조 알고리즘'이 밑에 자동으로 추천되는 원리가 궁금하신가요?
이러한 마법 같은 문자열 검색 및 자동완성에 특화된 자료구조가 바로 트라이(Trie)입니다. 트라이는 단어의 철자(알파벳 등) 하나하나를 노드로 쪼개어 트리 형태로 연결한 '접두사 트리(Prefix Tree)' 구조를 띕니다. 덕분에 문자열의 길이에만 비례하는 압도적인 검색 속도를 자랑합니다.
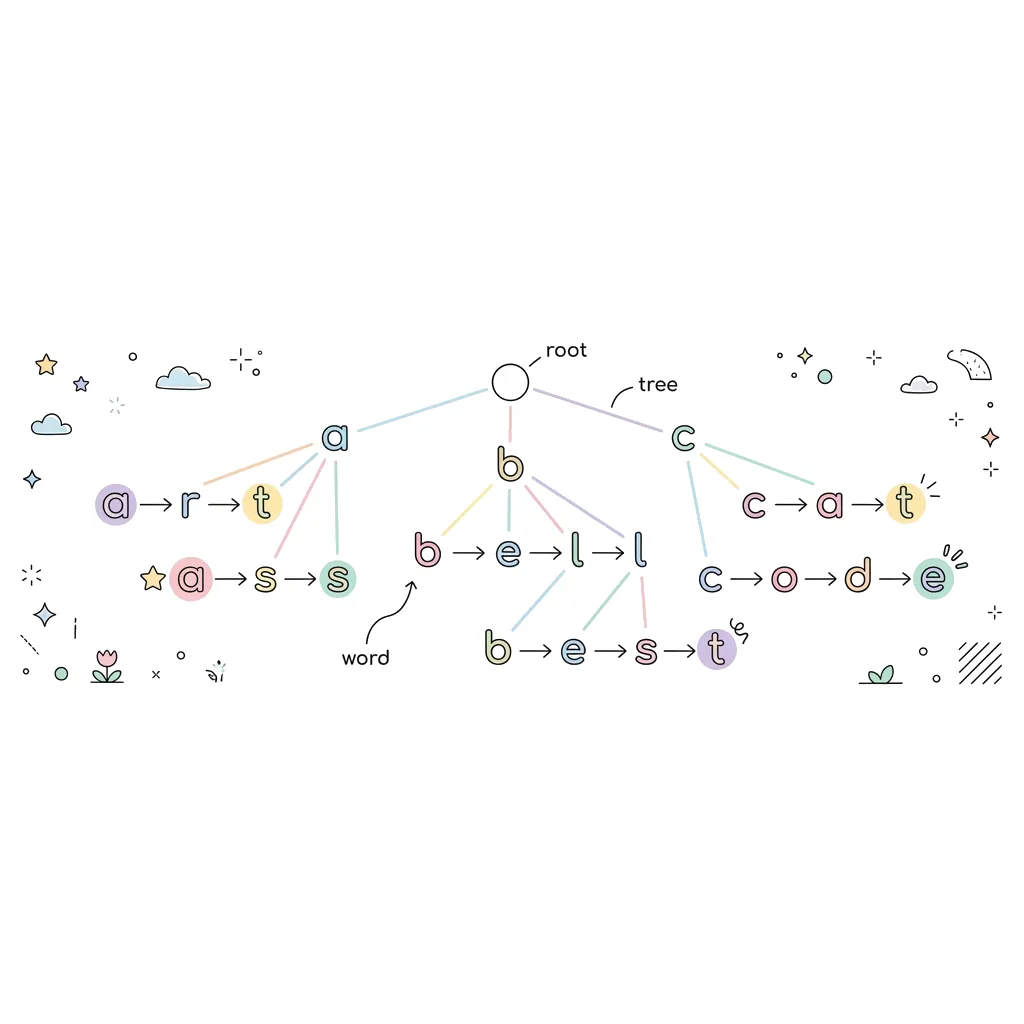
1. 트라이(Trie)의 구조와 원리
2. 트라이의 강력한 장점과 치명적인 단점
| 구분 | 내용 | 비고 |
|---|---|---|
| 강력한 장점 (속도) | 문자열의 최대 길이가 M일 때, 탐색 시간 복잡도는 무조건 O(M)입니다. 내부에 저장된 데이터(단어)가 1억 개라도 속도는 단어의 길이에만 좌우됩니다. |
일반적인 문자열 검색 시 O(N * M)에 비해 압도적 |
| 치명적인 단점 (메모리) | 모든 글자(알파벳 26자)마다 포인터 배열이나 해시맵 노드를 가져야 하므로 메모리 낭비가 매우 극심합니다. | 최적화를 위해 메모리를 덜 쓰는 Radix Tree나 Ternary Search Tree를 대체제로 쓰기도 함 |
💡 실무 지식: 검색어 자동완성은 트라이로만 만드나요?
알고리즘 인터뷰나 소규모 프로젝트에서는 트라이(Trie)가 자동완성의 정석입니다. 하지만 구글이나 쿠팡 같은 실제 대규모 환경에서는 트라이 하나만 쓰지 않습니다.
주로 ElasticSearch(엘라스틱서치)라는 검색 엔진을 활용해 Edge N-gram(글자를 쪼개어 인덱싱) 방식으로 구현하거나, 인기 검색어는 Redis의 Sorted Set을 사용해 캐싱하여 초고속으로 뿌려주는 방식을 훨씬 더 많이 사용합니다.
// 📂 Trie.js (JavaScript)
// 트라이 노드 클래스: 자식 노드들을 담는 객체와 단어의 끝임을 알리는 플래그를 가집니다.
class TrieNode {
constructor() {
this.children = {}; // 알파벳을 키로 하는 자식 노드들
this.isEndOfWord = false; // 단어의 끝(단어 완성) 여부
}
}
class Trie {
constructor() {
this.root = new TrieNode();
}
// 🌟 단어 삽입 (Insert)
insert(word) {
let current = this.root;
for (let i = 0; i < word.length; i++) {
let char = word[i];
if (!current.children[char]) {
current.children[char] = new TrieNode(); // 없으면 새로운 노드 생성
}
current = current.children[char]; // 다음 노드로 이동
}
current.isEndOfWord = true; // 마지막 글자 노드에 단어 끝 표시
}
// 🌟 단어 완전 일치 검색 (Search)
search(word) {
let current = this.root;
for (let i = 0; i < word.length; i++) {
let char = word[i];
if (!current.children[char]) return false; // 도중에 길이 끊기면 없음
current = current.children[char];
}
return current.isEndOfWord; // 마지막 글자까지 도달했고, 단어의 끝이라면 true
}
// 🌟 접두사(Prefix) 검색 (자동완성에 주로 사용됨)
startsWith(prefix) {
let current = this.root;
for (let i = 0; i < prefix.length; i++) {
let char = prefix[i];
if (!current.children[char]) return false;
current = current.children[char];
}
return true; // 접두사까지만 무사히 도달하면 true
}
}
// 🌐 테스트 실행
const trie = new Trie();
trie.insert("apple");
trie.insert("app");
console.log("apple 검색:", trie.search("apple")); // true
console.log("app 검색:", trie.search("app")); // true
console.log("appl 검색:", trie.search("appl")); // false (appl이라는 단어는 등록 안 됨)
console.log("app로 시작하는가?:", trie.startsWith("app")); // trueB-Tree & B+Tree
B-Tree & B+Tree (B-트리)
수천만 건의 데이터를 가진 MySQL, Oracle 등 데이터베이스(DB)는 어떻게 0.01초 만에 원하는 데이터를 쏙 빼올까요? 그 비밀 병기가 바로 B-Tree (Balanced Tree)와 그 발전형인 B+Tree입니다.
일반적인 이진 트리(Binary Tree)는 한 노드에 자식이 2개뿐이라 데이터가 많아지면 나무가 위아래로 매우 길어집니다. 반면 B-Tree는 하나의 노드 안에 수십~수백 개의 데이터(Key)를 구겨 넣고 가지를 여러 개 뻗는 '가로로 넓고 뚱뚱한(Fat & Shallow)' 구조를 택했습니다. 이 기발한 아이디어가 하드디스크(HDD/SSD)의 물리적 속도를 한계까지 끌어올렸습니다.
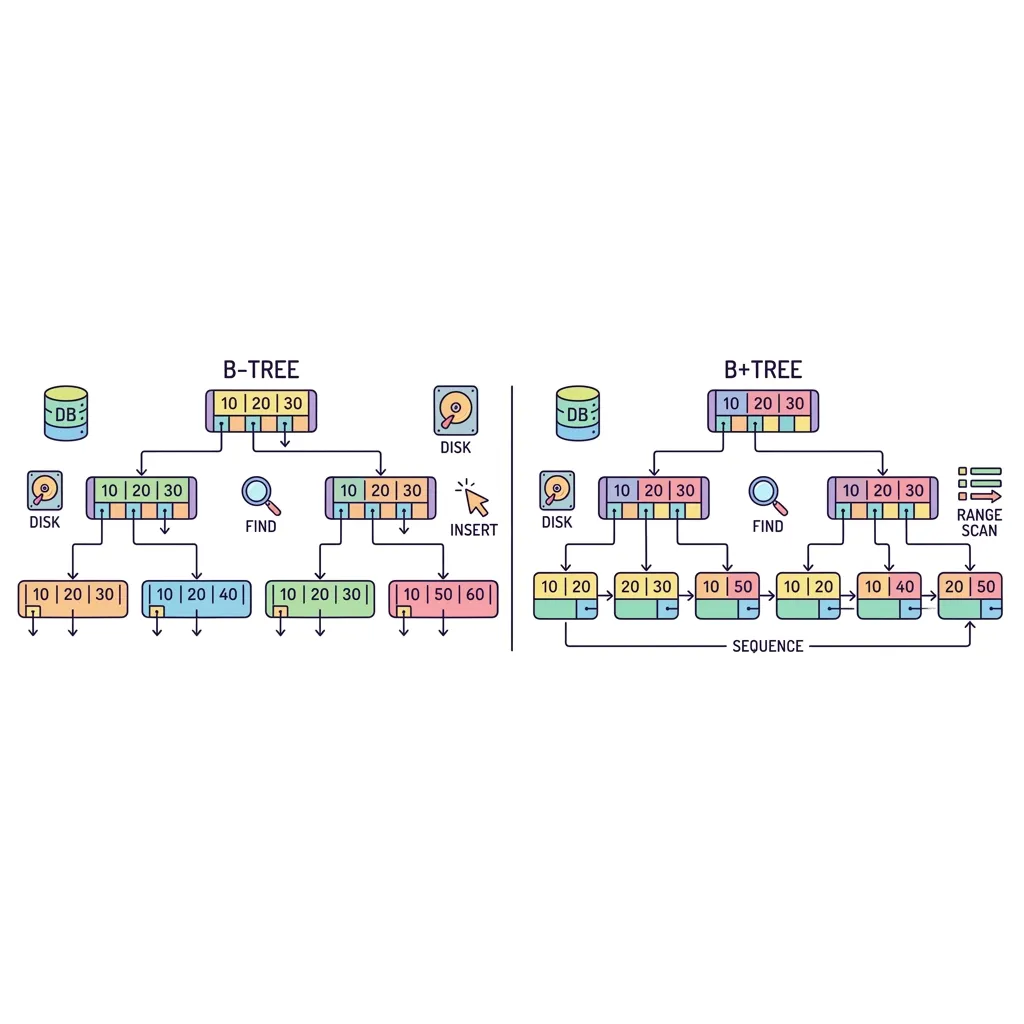
1. B-Tree의 구조: 왜 가로로 뚱뚱한가?
2. 디스크 I/O와 B-Tree의 궁합
컴퓨터에서 가장 느린 부품은 '하드디스크(SSD 포함)'입니다. 디스크에서 데이터를 한 번 퍼올릴 때마다 막대한 I/O 시간이 걸립니다.
- 이진 탐색 트리(BST): 100만 건 탐색 시 최악의 경우 트리 높이가 100만 층. 디스크를 최대 100만 번 긁어와야 함 (엄청난 속도 저하).
- B-Tree: 하나의 노드(디스크 블록 1페이지) 안에 100개의 키를 넣으면, 100갈래로 가지를 칩니다. 100만 건 데이터라도 트리 높이는 겨우 3층에 불과합니다. 즉, 디스크를 단 3번만 퍼올리면 데이터를 찾을 수 있습니다!
💡 실무 지식: B+Tree는 무엇이 다른가요?
B-Tree를 한 번 더 개량한 것이 B+Tree (MySQL InnoDB 기본 인덱스)입니다.
B-Tree는 모든 노드에 실제 데이터가 들어있지만, B+Tree는 중간 노드에는 이정표(Key)만 두고, 실제 데이터는 무조건 맨 아랫바닥(리프 노드)에만 몰아넣습니다.
그리고 바닥에 깔린 리프 노드들끼리 연결 리스트(Linked List)로 쭈욱 연결해 두었습니다. 덕분에 "10번부터 50번까지 쭉 가져와!" 같은 범위 검색(Range Scan)을 할 때, 트리를 오르락내리락 할 필요 없이 바닥에서 기차처럼 옆으로 쭉 긁어오기만 하면 되므로 성능이 폭발적으로 상승합니다.
// 📂 BTreeNode.js (JavaScript)
// B-Tree 노드의 핵심: 여러 개의 키(Keys)와 여러 개의 자식(Children)을 갖습니다.
class BTreeNode {
constructor(leaf = false) {
this.keys = []; // 노드가 가지는 데이터들 (항상 정렬된 상태 유지)
this.children = []; // 자식 노드를 가리키는 포인터들
this.leaf = leaf; // 단말 노드(맨 아래 노드)인지 여부
}
}
class BTree {
constructor(t) {
this.root = new BTreeNode(true);
this.t = t; // 최소 차수 (t가 2면 한 노드에 최대 3개의 키가 들어감)
}
// 데이터 검색 (이진 탐색 트리와 매우 유사하지만 여러 갈래로 나뉨)
search(node, key) {
let i = 0;
// 1. 현재 노드에서 나보다 크거나 같은 키를 찾을 때까지 오른쪽으로 이동
while (i < node.keys.length && key > node.keys[i]) {
i++;
}
// 2. 일치하는 키를 찾았다면 바로 해당 노드 반환!
if (i < node.keys.length && key === node.keys[i]) {
return { node, index: i };
}
// 3. 리프 노드인데도 못 찾았다면 데이터가 없는 것
if (node.leaf) {
return null;
}
// 4. 자식 노드로 내려가서 다시 재귀적으로 탐색
return this.search(node.children[i], key);
}
}
console.log("실제 RDBMS(MySQL 등)의 인덱스 검색은 이와 같은 방식으로 동작합니다.");레드-블랙 트리 (Red-Black Tree)
레드-블랙 트리 (Red-Black Tree)
기존의 이진 탐색 트리(BST)는 최악의 경우 데이터가 한쪽으로 쏠려(예: 1, 2, 3, 4 순서로 삽입 시) 일직선의 연결 리스트처럼 변해버리는 치명적인 약점이 있습니다. 이를 해결하기 위해 등장한 구세주가 바로 레드-블랙 트리(Red-Black Tree)입니다.
레드-블랙 트리는 노드에 '빨강(Red)'과 '검정(Black)'이라는 색상 속성을 부여하고, 데이터가 한쪽으로 쏠리려고 할 때마다 스스로 트리를 회전(Rotation)시키고 색상을 바꿔(Color Flip) 항상 완벽한 균형(Balance)을 유지합니다.
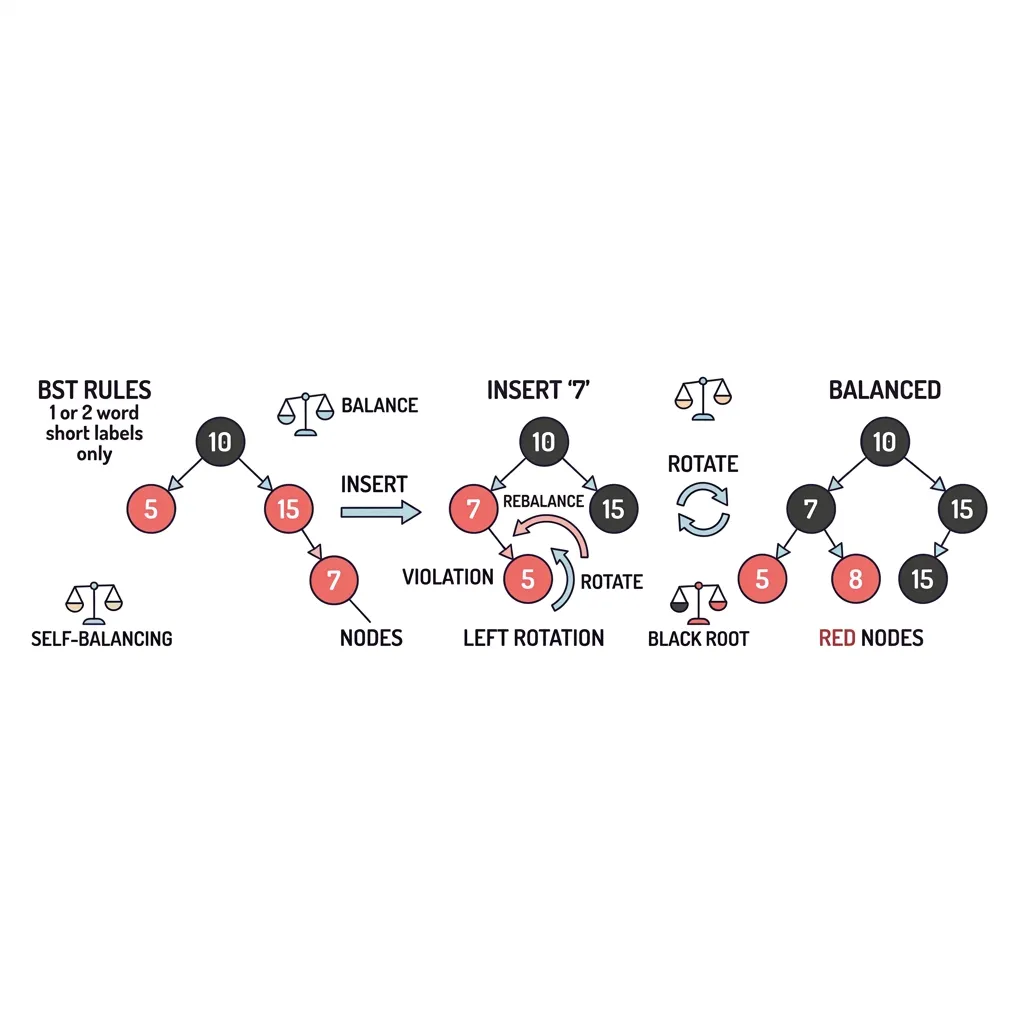
1. 절대 어길 수 없는 4가지 절대 규칙
레드-블랙 트리는 아래의 4가지 규칙을 무조건 지켜야 합니다. 이 규칙이 깨지는 순간 좌회전, 우회전, 색상 반전이라는 복구 작업이 실행됩니다.
- 규칙 1. 모든 노드는 빨간색(Red) 아니면 검은색(Black)이다.
- 규칙 2. 최상단 뿌리 노드(Root Node)는 무조건 검은색(Black)이다.
- 규칙 3 (Double Red 금지). 빨간색 노드의 자식은 연속으로 빨간색이 올 수 없다. (반드시 검은색이어야 함)
- 규칙 4 (Black Height 유지). 특정 노드에서 리프 노드 끝까지 내려가는 모든 경로에서 거치는 검은색 노드의 개수는 모두 똑같아야 한다.
2. 회전(Rotation)을 통한 자가 균형 시뮬레이션
💡 실무 지식: Java 컬렉션의 핵심 엔진
레드-블랙 트리는 구조가 매우 복잡해서 실제 실무 코드에서 밑바닥부터 짜는 경우는 극히 드뭅니다.
하지만 우리가 매일 쓰는 Java의 TreeMap, TreeSet, 그리고 C++의 std::map이 모두 내부적으로 이 레드-블랙 트리로 구현되어 있습니다. 즉, 여러분이 TreeMap을 사용해 데이터를 정렬할 때마다 보이지 않는 곳에서 수많은 노드들이 빨갛게, 검게 물들며 회전하고 있는 것입니다.
// 📂 RBTree.js (JavaScript)
// 레드-블랙 트리의 노드는 항상 '색상(Color)' 정보를 가집니다.
const RED = true;
const BLACK = false;
class Node {
constructor(key, color = RED) {
this.key = key;
this.left = null;
this.right = null;
this.parent = null; // 부모를 가리키는 포인터가 회전(Rotation) 시 필수적입니다.
this.color = color; // 새로 추가되는 노드는 무조건 RED로 시작합니다.
}
}
class RedBlackTree {
constructor() {
this.root = null;
}
// 🌟 핵심 원리: 좌회전 (Left Rotate)
// 오른쪽 자식이 무거워졌을 때, 중심축을 왼쪽으로 기울여 밸런스를 맞춥니다.
leftRotate(x) {
let y = x.right;
x.right = y.left;
if (y.left !== null) y.left.parent = x;
y.parent = x.parent;
if (x.parent === null) this.root = y;
else if (x === x.parent.left) x.parent.left = y;
else x.parent.right = y;
y.left = x;
x.parent = y;
console.log(`노드 ${x.key}를 기준으로 좌회전(Left-Rotate) 수행!`);
}
// 삽입 로직 (이진 트리 삽입 후 색상 규칙 위반 시 회전 및 색 변환 수행)
insert(key) {
// ... (이진 탐색 트리 삽입 코드) ...
// ... (삽입 후 fixViolation(newNode) 호출하여 RED-RED 충돌 해결) ...
console.log(`${key} 삽입 후 밸런스를 스스로 맞춥니다.`);
}
}
const rbt = new RedBlackTree();
rbt.insert(10);
rbt.insert(20);
rbt.insert(30); // 10-20-30 일직선 시 Left-Rotate 발생!블룸 필터 (Bloom Filter)
블룸 필터 (Bloom Filter)
구글 크롬 브라우저는 수억 개의 "악성 사이트 URL 목록"을 어떻게 메모리 부족 없이 초고속으로 검사할까요? 정답은 블룸 필터(Bloom Filter)에 있습니다.
블룸 필터는 원본 데이터를 통째로 저장하지 않고, 여러 개의 해시 함수(Hash Function)를 돌려서 아주 작은 '비트 배열(Bit Array)'에 점(1)만 찍어두는 방식입니다. 덕분에 수 기가바이트(GB)의 데이터를 고작 몇 메가바이트(MB)의 메모리만으로 압축하여 "이 데이터가 존재하는가?"를 빛의 속도로 알아낼 수 있습니다.
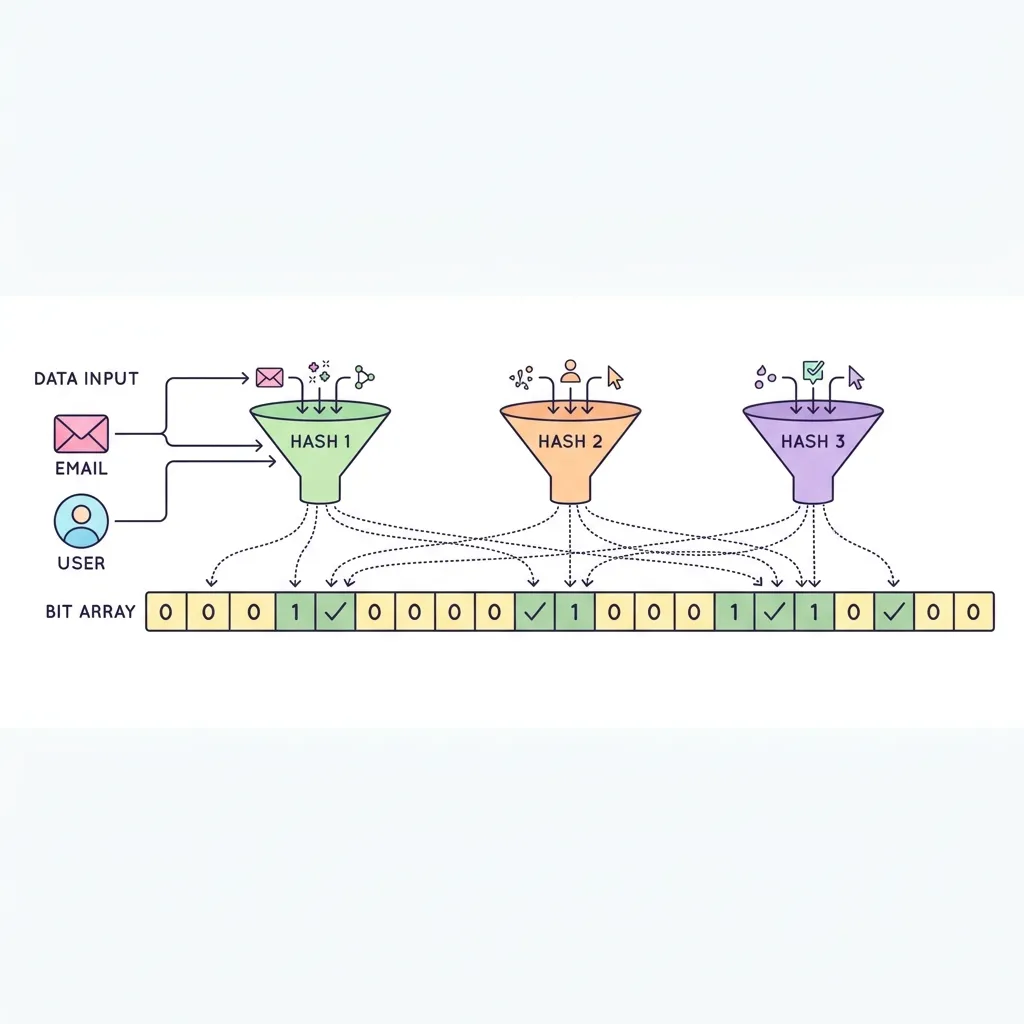
1. "절대 없음(100%)"과 "있을지도 모름(99%)"의 미학
블룸 필터는 메모리를 극한으로 아끼는 대신, 약간의 타협을 했습니다. 바로 "False Positive (오탐지)"입니다. 여러 데이터가 우연히 같은 비트 자리를 공유할 수 있기 때문입니다.
- 해시를 돌렸을 때 하나라도 0이 나온다면? 👉 100% 확실하게 없음! (DB를 조회할 필요도 없음)
- 해시를 돌렸을 때 모두 1이 나온다면? 👉 있을 확률이 매우 높음! (하지만 다른 데이터들이 우연히 찍어놓은 흔적일 수도 있음. 이때만 진짜 DB를 조회해봄)
2. 비트 배열(Bit Array)에 마킹되는 과정
💡 실무 지식: 레디스(Redis) 캐시 폭격(Cache Stampede) 방지
초당 수만 명이 접속하는 서비스에서, 악의적인 해커가 "존재하지도 않는 회원 ID"로 미친듯이 검색을 요청하면 어떻게 될까요?
캐시(Redis)에 데이터가 없으므로 모든 요청이 메인 DB로 직행하여 DB가 뻗어버립니다(Cache Penetration). 이때 메인 DB 앞단에 블룸 필터를 설치해 두면, "없는 회원"이라는 것을 블룸 필터가 0.0001초 만에 걸러내어 DB를 완벽하게 보호해 줍니다!
// 📂 BloomFilter.js (JavaScript)
// 해시 함수를 여러 개 사용하여 비트 배열(Bit Array)에 마킹합니다.
class BloomFilter {
constructor(size = 100) {
this.size = size;
this.bitArray = new Array(size).fill(0); // 0으로 초기화된 비트 배열
}
// 간단한 해시 함수 3개 (실무에서는 MurmurHash 등 빠르고 고른 해시 사용)
hash1(item) {
let hash = 0;
for (let i = 0; i < item.length; i++) hash += item.charCodeAt(i);
return hash % this.size;
}
hash2(item) {
let hash = 0;
for (let i = 0; i < item.length; i++) hash += (item.charCodeAt(i) * 7);
return hash % this.size;
}
hash3(item) {
let hash = 0;
for (let i = 0; i < item.length; i++) hash += (item.charCodeAt(i) * 13);
return hash % this.size;
}
// 🌟 데이터 삽입 (비트를 1로 마킹)
add(item) {
this.bitArray[this.hash1(item)] = 1;
this.bitArray[this.hash2(item)] = 1;
this.bitArray[this.hash3(item)] = 1;
}
// 🌟 데이터 존재 여부 확인
mightContain(item) {
// 세 개의 해시 결과 위치가 모두 1인지 확인합니다.
// 단 하나라도 0이라면 "절대 없음(100%)"을 확신할 수 있습니다.
return this.bitArray[this.hash1(item)] === 1 &&
this.bitArray[this.hash2(item)] === 1 &&
this.bitArray[this.hash3(item)] === 1;
}
}
// 🌐 테스트 실행
const filter = new BloomFilter(100);
filter.add("minstudio");
filter.add("youtube");
console.log("minstudio가 있나요?", filter.mightContain("minstudio")); // true
console.log("netflix가 있나요?", filter.mightContain("netflix")); // false (없음 확실!)유니온 파인드 (Union-Find)
유니온 파인드 (Union-Find)
카카오톡 친구 추천에서 "A와 B가 친구이고, B와 C가 친구이면 A와 C도 알 수도 있는 사람"으로 묶이는 원리를 아시나요?
이처럼 여러 개의 점(노드)들이 서로 같은 네트워크(집합)에 속해 있는지 빠르게 확인하고 합칠 때 사용하는 마법 같은 알고리즘이 바로 유니온 파인드(서로소 집합, Disjoint Set)입니다. 오직 1차원 배열 하나만으로 복잡한 그래프의 연결 상태를 O(1)에 가깝게 파악할 수 있는 극강의 효율을 자랑합니다.
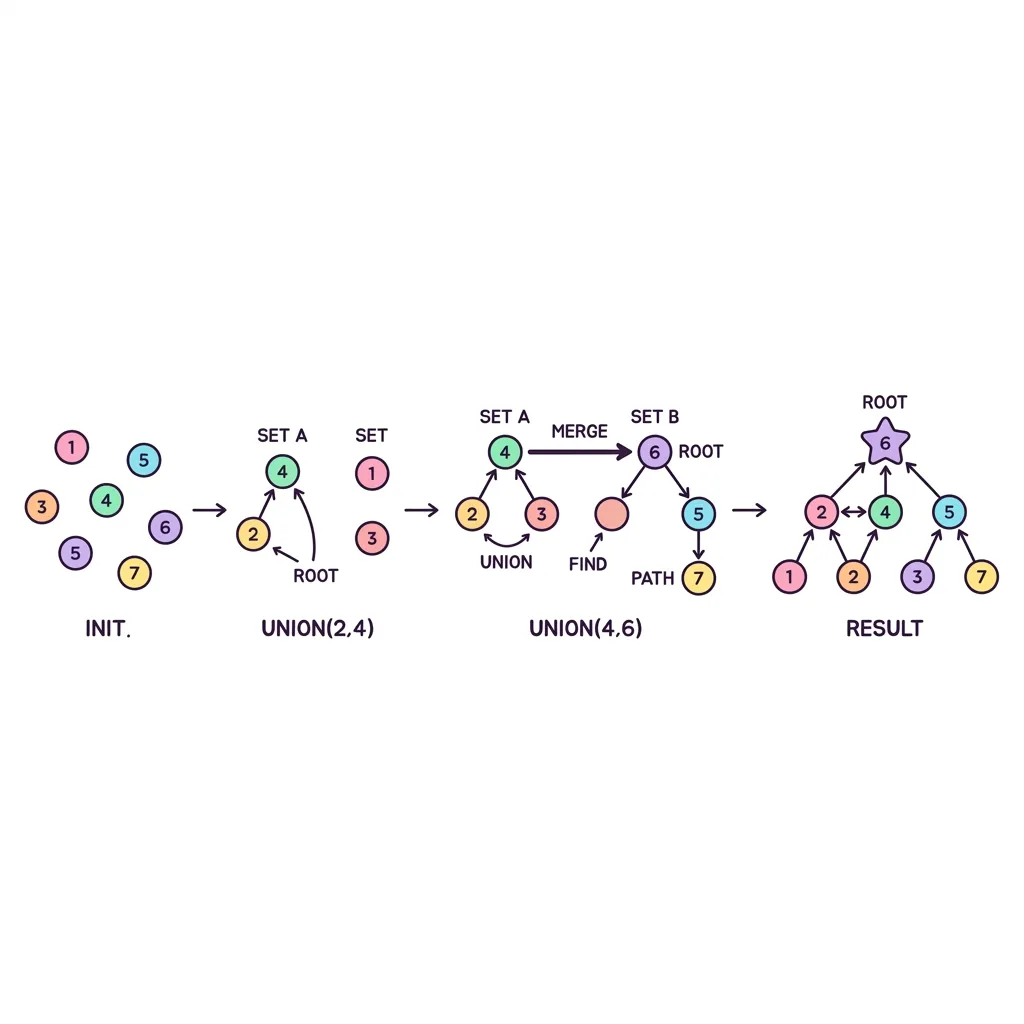
1. Union(합치기)과 Find(대장 찾기)
2. 핵심 치트키: 경로 압축 (Path Compression)
만약 데이터가 1-2-3-4-5 처럼 기차놀이 하듯 한 줄로만 길게 연결된다면 대장을 찾는데(Find) 시간이 오래 걸릴 것입니다.
이를 방지하기 위해 Find를 수행하면서 거쳐간 모든 꼬봉 노드들이 직접 최상위 대장을 가리키도록 배열 값을 업데이트합니다. 이것이 바로 유니온 파인드 속도의 핵심인 경로 압축(Path Compression)입니다.
// 자바스크립트 기준 경로 압축 코드
find(x) {
if (parent[x] === x) return x;
// 재귀적으로 대장을 찾으면서 내 부모값을 대장으로 덮어씀
return parent[x] = find(parent[x]);
}
💡 실무 지식: 도대체 언제 쓰나요?
- 최소 신장 트리 (MST): 네트워크 케이블 깔기, 최단 경로 길찾기 등 크루스칼(Kruskal) 알고리즘에서 사이클이 생기는지 방지할 때 무조건 쓰입니다.
- 네트워크 및 소셜 연결 분석: "이 유저와 저 유저가 몇 다리 건너면 아는 사이인가?"를 판별하는 클러스터링 알고리즘에서 맹활약합니다.
// 📂 UnionFind.js (JavaScript)
// 1차원 배열(parent) 하나로 모든 집합 관계를 완벽하게 표현합니다.
class UnionFind {
constructor(size) {
// 처음에는 자기 자신을 부모로 가리킵니다. (각자 독립된 집합)
this.parent = Array.from({ length: size }, (_, i) => i);
}
// 🌟 Find: 자신이 속한 집합의 대장(Root)을 찾습니다.
find(x) {
if (this.parent[x] === x) {
return x; // 자신이 대장이면 그대로 반환
}
// 💡 경로 압축(Path Compression)
// 대장을 찾는 길에 만나는 모든 노드들이 직접 대장을 가리키게 만듭니다. (속도 극대화)
this.parent[x] = this.find(this.parent[x]);
return this.parent[x];
}
// 🌟 Union: 두 집합을 하나로 합칩니다.
union(a, b) {
let rootA = this.find(a);
let rootB = this.find(b);
if (rootA !== rootB) {
this.parent[rootB] = rootA; // B의 대장을 A의 대장 밑으로 편입시킵니다.
}
}
// 두 노드가 같은 집합에 있는지 확인
isConnected(a, b) {
return this.find(a) === this.find(b);
}
}
// 🌐 테스트 실행
const uf = new UnionFind(10);
uf.union(1, 2);
uf.union(2, 3);
uf.union(4, 5);
console.log("1과 3은 같은 네트워크인가요?", uf.isConnected(1, 3)); // true (1-2-3 연결됨)
console.log("1과 5는 같은 네트워크인가요?", uf.isConnected(1, 5)); // false