삽입 정렬 (Insertion Sort)
삽입 정렬 (Insertion Sort)
삽입 정렬(Insertion Sort)은 두 번째 요소부터 시작하여 그 앞의 이미 정렬된 부분(Sorted Portion)과 비교해 자신이 들어갈 올바른 위치를 찾아 삽입(Insert)하는 알고리즘입니다. 손에 쥔 트럼프 카드들을 오름차순으로 정리할 때 사용하는 방법과 원리가 완전히 동일합니다.
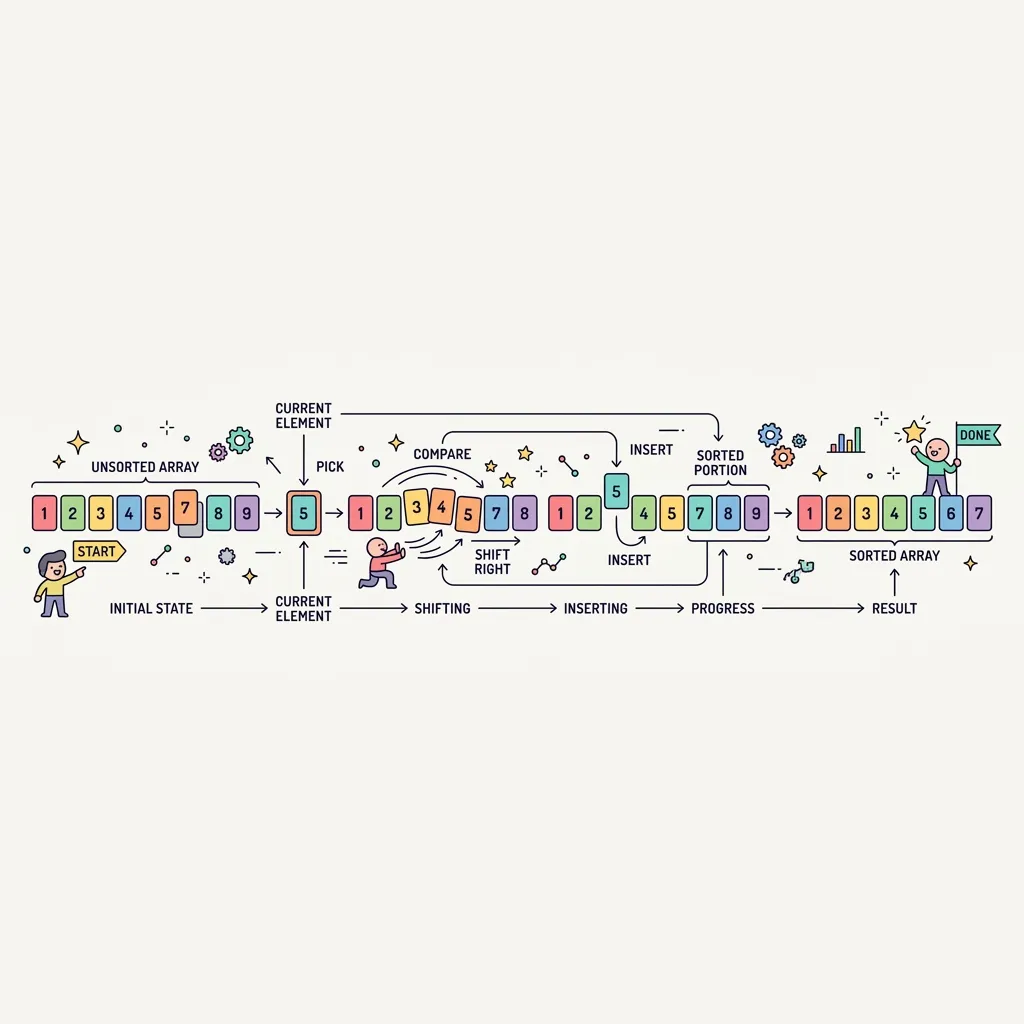
1. 삽입 정렬의 작동 원리
선택 정렬이나 버블 정렬에 비해 실질적인 데이터 이동 횟수가 적어 기본 정렬 알고리즘 중에서는 가장 빠르다고 평가받습니다.
● 기준 설정(Key) : 두 번째 위치(인덱스 1)의 값을 Key로 지정하고 시작합니다.
● 밀어내기(Shifting) : 앞쪽의 정렬된 요소들을 역순으로 탐색하며 Key보다 큰 값이 있으면 그 값을 오른쪽으로 한 칸씩 밉니다.
● 삽입(Insertion) : Key보다 작거나 같은 값을 만나면 탐색을 멈추고, 그 바로 뒷자리에 Key를 꽂아 넣습니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선 시간 복잡도 (Best) | O(N) | 배열이 이미 정렬되어 있는 경우, 앞 요소와 단 한 번만 비교하고 바로 다음 요소로 넘어가기 때문에 탐색 속도가 압도적으로 빠릅니다. |
| 최악/평균 시간 복잡도 | O(N²) | 배열이 역순으로 정렬되어 있다면 매번 첫 번째 자리까지 모든 요소를 밀어내야(Shift) 하므로 엄청난 오버헤드가 발생합니다. |
| 공간 복잡도 | O(1) | 주어진 배열 안에서 값들을 Shift하고 끼워 넣는 제자리 정렬이므로 추가 공간이 불필요합니다. |
💡 실무 지식: 안정 정렬(Stable Sort)과 Timsort
삽입 정렬은 중복된 값의 원래 순서를 그대로 유지해주는 안정 정렬(Stable Sort)입니다. O(N²) 이라서 실무에서 단독으로는 안 쓰이지만, 크기가 아주 작은 배열이거나 이미 거의 정렬된 배열에서는 퀵 정렬보다도 훨씬 빠르다는 엄청난 장점이 있습니다. 이 성질을 이용하여 V8 자바스크립트 엔진이나 Python은 '일정 크기 이하로 분할된 배열'을 정렬할 때 병합 정렬과 삽입 정렬을 섞어 쓰는 Timsort 하이브리드 알고리즘을 사용합니다.
// JavaScript 구현
function insertionSort(arr) {
const n = arr.length;
console.log("초기 배열:", arr);
// 두 번째 요소(인덱스 1)부터 탐색 시작
for (let i = 1; i < n; i++) {
let key = arr[i];
let j = i - 1;
// key보다 큰 값들은 한 칸씩 오른쪽으로 이동(Shift)
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
// 알맞은 위치에 key 삽입
arr[j + 1] = key;
}
return arr;
}
const arr = [5, 3, 1, 4, 2];
console.log("정렬 결과:", insertionSort(arr));이진 탐색 (Binary Search)
이진 탐색 (Binary Search)
이진 탐색(Binary Search)은 반드시 정렬되어 있는 배열에서 특정한 값을 찾아내는 매우 빠르고 강력한 탐색 알고리즘입니다. 우리가 흔히 하는 '업다운(Up-Down) 게임'처럼 매번 탐색 범위를 절반씩 뚝뚝 잘라내가며 정답을 압축해 들어가는 방식입니다.
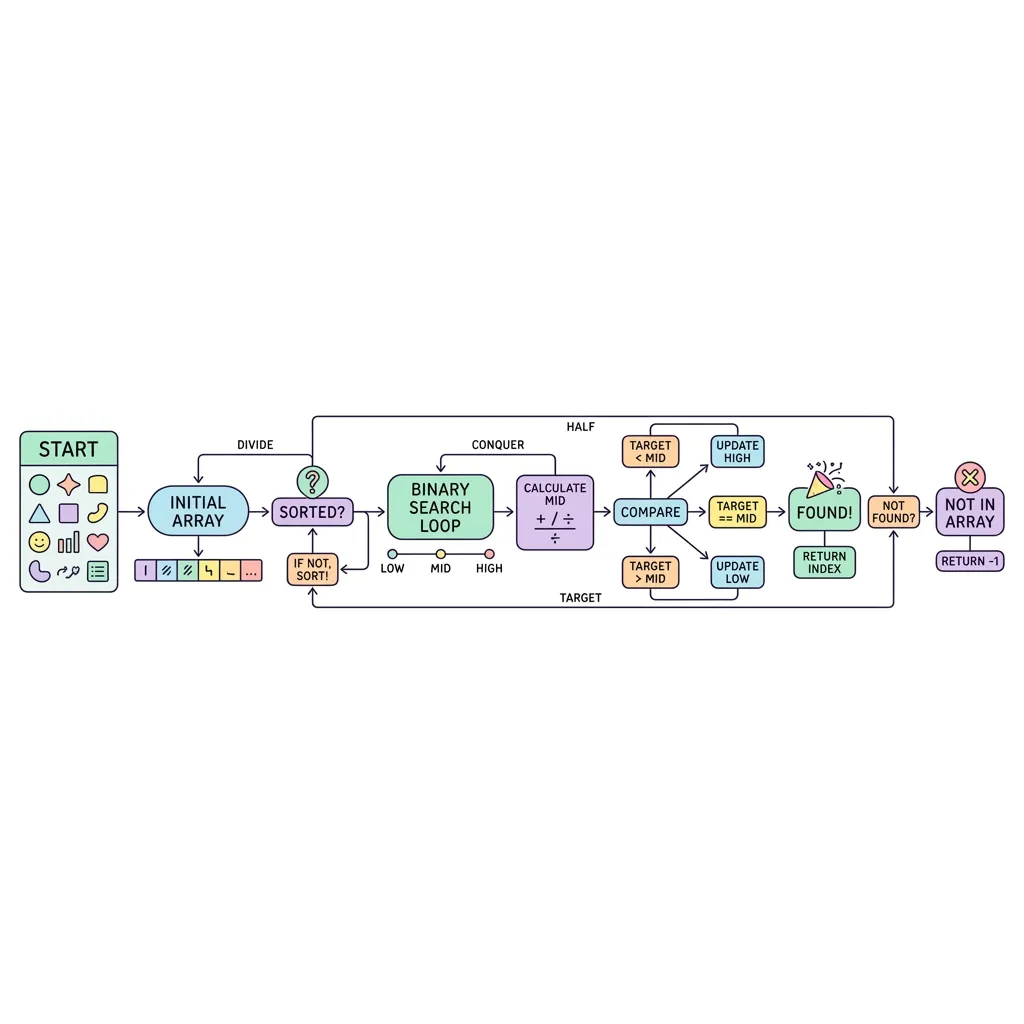
1. 이진 탐색의 작동 원리
이진 탐색은 분할 정복(Divide and Conquer)의 철학을 가장 잘 보여주는 탐색 기법입니다.
● 중앙값 비교 : 탐색 범위의 정중앙에 있는 값(Mid)을 선택해 찾고자 하는 타겟(Target)과 비교합니다.
● 범위 반갈죽(Half Discard) : 타겟이 중앙값보다 크다면 중앙값 기준 왼쪽 절반을 완전히 버리고 오른쪽만 탐색합니다(작다면 반대).
● 전제 조건 : 이 알고리즘이 성립하려면 데이터는 무조건 오름차순(또는 내림차순)으로 정렬되어 있어야만 합니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선 시간 복잡도 (Best) | O(1) | 처음 계산한 한가운데(Mid) 값이 우연히 우리가 찾으려던 타겟과 정확히 일치할 때입니다. |
| 평균/최악 시간 복잡도 | O(log N) | 순차 탐색 O(N)에 비해 기적적으로 빠릅니다. 예를 들어 43억 개의 데이터가 있어도 최대 32번만 비교하면 무조건 정답을 찾아냅니다. |
| 공간 복잡도 | O(1) | 반복문(while)으로 구현할 경우 Left, Right, Mid 포인터 변수만 있으면 되므로 별도 메모리를 차지하지 않습니다. |
💡 실무 지식: 오버플로우 방지 팁
자바(Java)나 C++ 같은 강타입 언어에서 mid = (left + right) / 2를 사용하면, 배열 크기가 엄청나게 클 경우 left + right 값이 int 자료형의 최댓값을 초과하여 오버플로우(Overflow) 에러가 발생할 수 있습니다. 실무에서는 이를 방지하기 위해 mid = left + (right - left) / 2 공식이나 비트 시프트 연산 (left + right) >>> 1을 사용하는 것이 정석입니다.
// JavaScript 구현
function binarySearch(arr, target) {
let left = 0;
let right = arr.length - 1;
while (left <= right) {
// 소수점 버림 방지 및 오버플로우 방지 공식 적용 권장
let mid = left + Math.floor((right - left) / 2);
console.log(`탐색 범위: index ${left} ~ ${right}, 중간값: ${arr[mid]}`);
if (arr[mid] === target) {
return mid; // 타겟을 찾음
} else if (arr[mid] < target) {
left = mid + 1; // 타겟이 오른쪽에 있음 -> 왼쪽 범위 버림
} else {
right = mid - 1; // 타겟이 왼쪽에 있음 -> 오른쪽 범위 버림
}
}
return -1; // 타겟이 배열에 없음
}
const sortedArr = [1, 3, 5, 7, 9, 11, 13, 15];
const target = 11;
console.log("배열:", sortedArr);
console.log(`타겟 ${target}의 인덱스:`, binarySearch(sortedArr, target));버블 정렬 (Bubble Sort)
버블 정렬 (Bubble Sort)
버블 정렬(Bubble Sort)은 서로 인접한 두 원소를 검사하여 정렬하는 알고리즘입니다. 큰 값이 마치 물속의 거품(Bubble)처럼 수면(배열의 맨 끝) 위로 하나씩 밀려 올라가는 모습과 닮았다고 해서 붙여진 이름입니다.
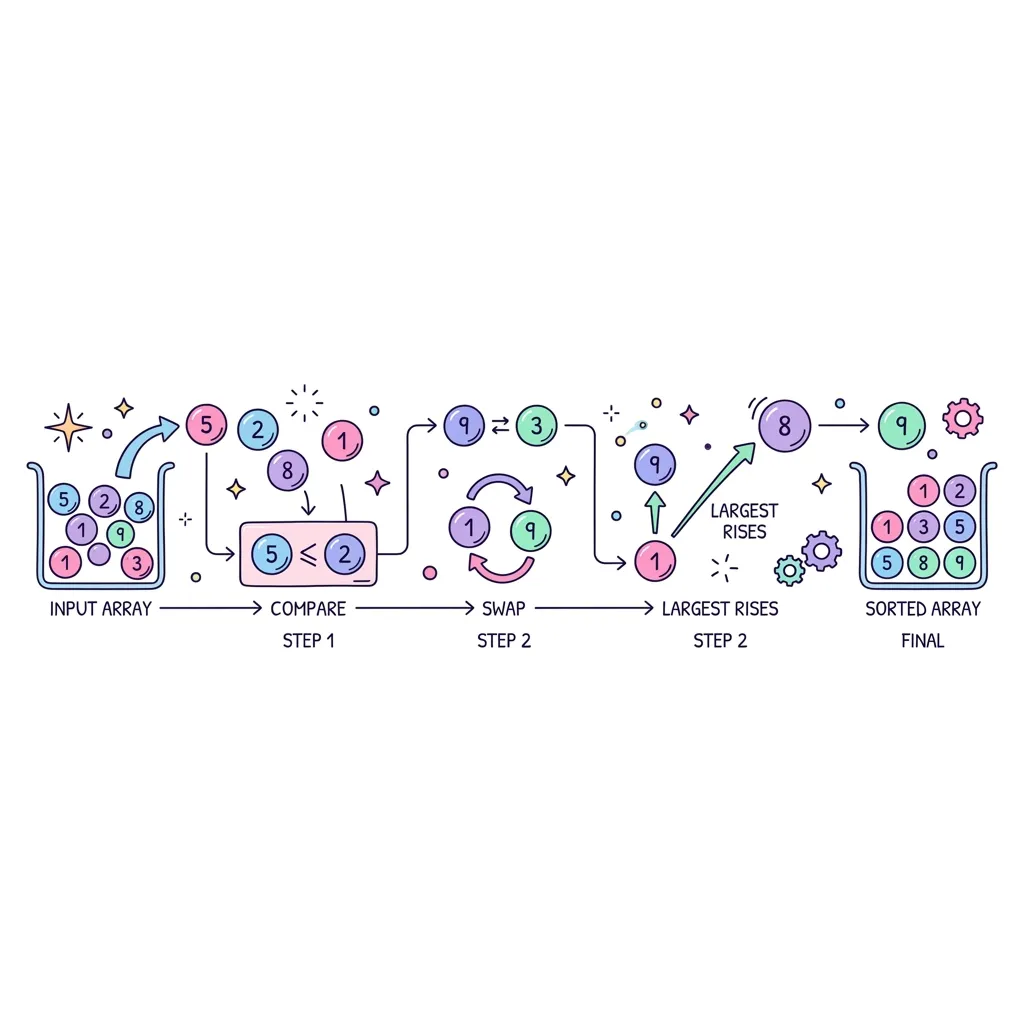
1. 버블 정렬의 작동 원리
버블 정렬은 정렬 알고리즘 중에서 구현이 가장 쉽지만, 실무 성능은 가장 처참한 알고리즘입니다.
● 인접 비교 : 첫 번째와 두 번째, 두 번째와 세 번째 등 바로 옆에 있는 데이터끼리만 계속 비교합니다.
● 교환(Swap) : 앞의 값이 뒤의 값보다 크면 자리를 바꿉니다(오름차순 기준).
● 확정 : 이렇게 배열을 한 바퀴(1 Pass) 다 돌고 나면, 현재 배열에서 가장 큰 값이 맨 마지막 자리로 이동하여 확정됩니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선 시간 복잡도 (Best) | O(N) | 배열이 이미 정렬되어 있는 경우입니다. swapped 플래그 최적화를 적용하면 첫 번째 바퀴(Pass)를 돌 때 단 한 번도 Swap이 일어나지 않으므로 즉시 O(N)으로 종료할 수 있습니다. |
| 평균/최악 시간 복잡도 | O(N²) | 배열이 역순인 최악의 경우, 이중 for문 안에서 매번 비교와 자리 교환(Swap) 연산이 발생합니다. 메모리 읽기/쓰기가 폭발적으로 일어나므로 N² 중에서도 가장 느립니다. |
| 공간 복잡도 | O(1) | 주어진 배열 내부에서 원소들의 자리만 바꾸는 제자리 정렬(In-place Sort)이므로 추가 메모리가 필요 없습니다. |
💡 실무 지식: Swapped 플래그 최적화
기본적인 버블 정렬은 배열이 이미 100% 정렬되어 있더라도 무식하게 끝까지 이중 for문을 돌며 O(N²)을 소모합니다. 이를 방지하기 위해 안쪽 루프를 도는 동안 한 번이라도 Swap이 발생했는지를 기록하는 boolean swapped 변수를 사용합니다. 한 바퀴를 돌았는데 Swap이 한 번도 안 일어났다면 이미 정렬이 끝났다는 뜻이므로 바깥쪽 루프를 과감하게 break 해버리는 것이 실무형 버블 정렬의 기본입니다.
// JavaScript 구현 (Swapped 최적화 적용)
function bubbleSort(arr) {
const n = arr.length;
console.log("초기 배열:", arr);
for (let i = 0; i < n - 1; i++) {
let swapped = false; // 이번 턴에 Swap이 일어났는지 추적
// 매 패스마다 가장 큰 값이 뒤로 확정되므로 끝에서 i만큼 빼줌
for (let j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 배열 구조 분해 할당을 이용한 Swap
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
swapped = true;
}
}
// 한 바퀴 돌았는데 단 한 번도 안 바뀌었다면? 이미 정렬 완료!
if (!swapped) break;
}
return arr;
}
const arr = [5, 3, 1, 4, 2];
console.log("정렬 결과:", bubbleSort(arr));선택 정렬 (Selection Sort)
선택 정렬 (Selection Sort)
선택 정렬(Selection Sort)은 각 순서에 넣을 요소의 '위치'는 이미 정해져 있고, 아직 정렬되지 않은 나머지 배열 중에서 가장 작은(또는 큰) 값을 계속 '선택'하여 정해진 위치의 요소와 교환(Swap)하는 매우 직관적이고 단순한 제자리 정렬 알고리즘입니다.
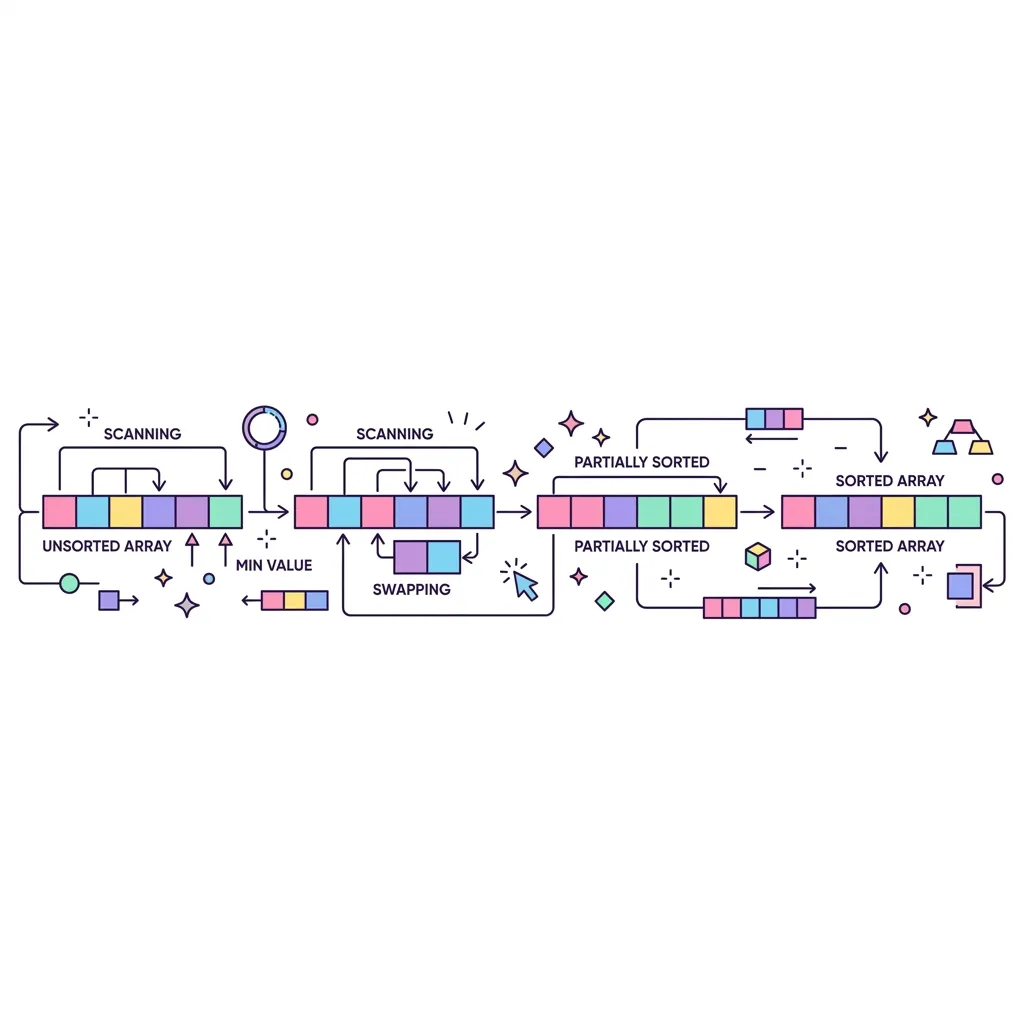
1. 선택 정렬의 작동 원리
버블 정렬(Bubble Sort)과 마찬가지로 동작은 단순하지만 교환 횟수가 적다는 특징이 있습니다.
● 최솟값 탐색(Scanning) : 현재 인덱스부터 배열의 끝까지 모두 훑으면서 가장 작은 값을 찾습니다.
● 교환(Swapping) : 찾아낸 최솟값을 현재 인덱스의 값과 자리를 바꿉니다.
● 반복(Iteration) : 인덱스를 1씩 늘려가며 위 과정을 배열 끝까지 반복합니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선/평균/최악 시간 복잡도 | O(N²) | 데이터가 이미 정렬되어 있든 역순이든 상관없이 무조건 배열 전체를 탐색하여 최소값을 찾아야 하므로 언제나 N(N-1)/2 번의 비교를 수행합니다. |
| 공간 복잡도 | O(1) | 주어진 배열 안에서 값의 위치만 교환하는 제자리 정렬(In-place Sort)이므로 별도의 추가 메모리 공간이 필요하지 않습니다. |
💡 실무 지식: 불안정 정렬(Unstable Sort)의 한계
선택 정렬은 동일한 값을 가진 요소들의 상대적인 순서가 뒤바뀔 수 있는 불안정 정렬(Unstable Sort)입니다. 예를 들어 [5A, 5B, 1] 이라는 배열에서 최솟값 1과 맨 앞의 5A를 교환하면 [1, 5B, 5A]가 되어 5A와 5B의 원래 순서가 역전됩니다. O(N²) 이라는 한계와 맞물려 실제 서비스에서는 거의 사용되지 않으며 알고리즘 학습용으로 주로 다뤄집니다.
// JavaScript 구현
function selectionSort(arr) {
const n = arr.length;
console.log("초기 배열:", arr);
for (let i = 0; i < n - 1; i++) {
let minIdx = i;
// 현재 인덱스 이후부터 최소값의 인덱스를 찾음
for (let j = i + 1; j < n; j++) {
if (arr[j] < arr[minIdx]) {
minIdx = j;
}
}
// 최소값이 자기 자신이 아니라면 스왑(Swap)
if (minIdx !== i) {
let temp = arr[i];
arr[i] = arr[minIdx];
arr[minIdx] = temp;
}
}
return arr;
}
const arr = [5, 3, 1, 4, 2];
console.log("정렬 결과:", selectionSort(arr));병합 정렬 (Merge Sort)
병합 정렬 (Merge Sort)
병합 정렬(Merge Sort)은 1945년 폰 노이만(John von Neumann)에 의해 개발된 알고리즘으로, 대표적인 분할 정복(Divide and Conquer) 패러다임을 사용하는 빠르고 안정적인 정렬 알고리즘입니다. 하나의 배열을 두 개의 균등한 크기로 끝까지 분할한 뒤, 부분 배열을 정렬하면서 다시 하나로 병합하는 과정을 거칩니다.
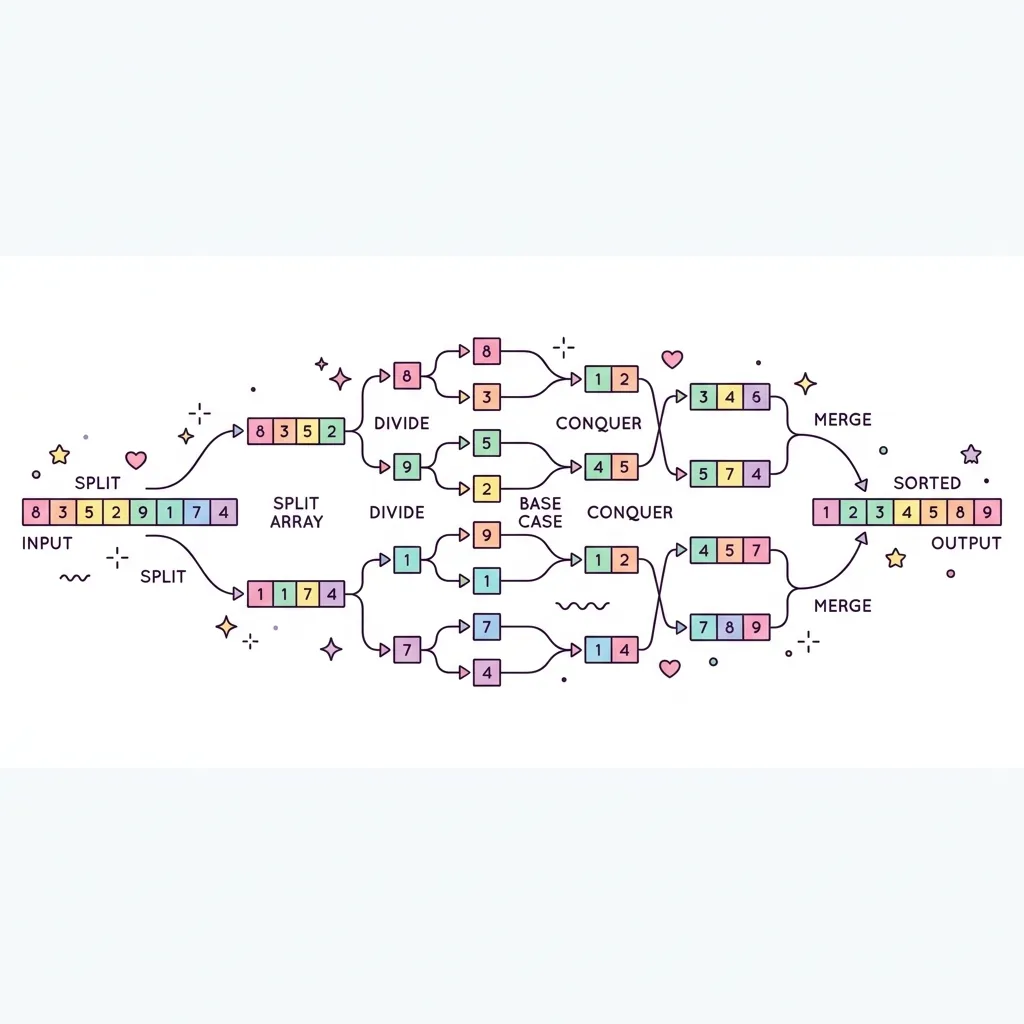
1. 분할 정복 (Divide and Conquer)이란?
병합 정렬은 다음 3단계의 논리적 흐름에 따라 작동합니다:
● Divide (분할) : 배열을 더 이상 나눌 수 없을 때까지(크기가 1이 될 때까지) 정확히 절반씩 나눕니다.
● Conquer (정복) : 나누어진 각 부분 배열을 정렬합니다. (요소가 1개라면 이미 정렬된 상태로 간주합니다.)
● Combine (결합) : 정렬된 부분 배열들을 두 개씩 묶어서 하나의 정렬된 배열로 병합(Merge) 합니다.
2. 병합 정렬의 주요 특징
[1] 안정 정렬 (Stable Sort)
배열 안에 값이 같은 두 요소가 있을 때, 정렬 후에도 그들의 상대적인 원래 순서가 변하지 않는 정렬입니다. 객체나 복합 데이터를 정렬할 때 기존의 정렬 기준이 유지되므로 매우 중요합니다.
[2] 일관된 성능 보장
데이터의 원래 분포 상태와 관계없이 언제나 배열을 반으로 나누기 때문에, 퀵 정렬(Quick Sort)의 최악의 경우(O(N²))와 같은 현상이 절대 발생하지 않고 어떤 상황에서도 O(N log N)의 성능을 보장합니다.
[3] 연결 리스트 (Linked List) 정렬에 탁월
순차적으로 데이터를 읽는 데 최적화되어 있어, 연결 리스트를 정렬할 때 배열보다 훨씬 빠르게 동작합니다.
3. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선/평균/최악 시간 복잡도 | O(N log N) | 크기가 N인 배열을 매번 1/2씩 계속 나누므로 트리의 높이는 log N이 됩니다. 각 높이(단계)마다 모든 요소(N개)를 스캔하며 병합하므로 단계당 비용은 O(N)이 소요됩니다. 따라서 전체는 O(N log N)입니다. |
| 공간 복잡도 | O(N) | 병합된 부분 배열을 임시로 저장할 배열 공간이 요소 개수(N)만큼 추가로 필요합니다. (In-place 정렬이 아님) |
💡 실무 지식: 퀵 정렬 vs 병합 정렬
일반적으로 배열을 다룰 때, 메모리 복사가 불필요한 퀵 정렬(Quick Sort)이 캐시 지역성(Cache Locality) 측면에서 병합 정렬보다 평균 20% 더 빠릅니다. 하지만, 최악의 성능 하락을 절대 용납할 수 없는 시스템 커널이나 표준 라이브러리(Java의 Arrays.sort() 등)에서는 병합 정렬의 변형(Timsort 등)이 더 널리 사용됩니다.
// JavaScript 구현
function mergeSort(arr) {
if (arr.length <= 1) return arr;
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(left, right) {
let result = [];
let i = 0, j = 0;
while (i < left.length && j < right.length) {
if (left[i] < right[j]) {
result.push(left[i]);
i++;
} else {
result.push(right[j]);
j++;
}
}
return result.concat(left.slice(i)).concat(right.slice(j));
}
const arr = [38, 27, 43, 3, 9, 82, 10];
console.log("초기 배열:", arr);
console.log("정렬 결과:", mergeSort(arr));퀵 정렬 (Quick Sort)
퀵 정렬 (Quick Sort)
퀵 정렬(Quick Sort)은 1959년 토니 호어(Tony Hoare)가 고안한 매우 빠르고 효율적인 정렬 알고리즘입니다. 피벗(Pivot)을 기준으로 배열을 작은 값과 큰 값 두 부분으로 분할(Partitioning)한 뒤, 각 부분을 재귀적으로 정렬하는 분할 정복(Divide and Conquer) 방법을 사용합니다. 범용적으로 가장 널리 쓰이는 정렬 알고리즘입니다.
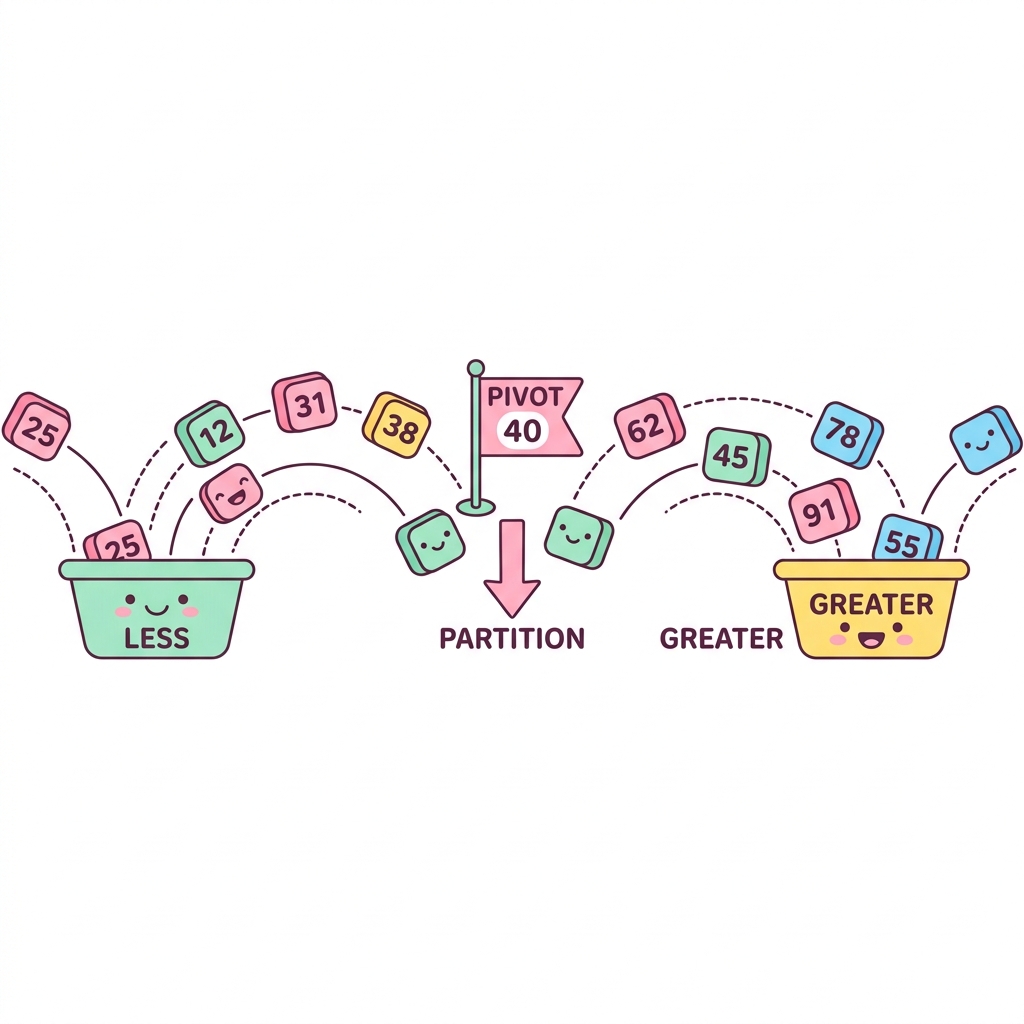
1. 퀵 정렬의 작동 원리 (Partitioning)
퀵 정렬의 핵심은 피벗(Pivot) 선정과 이를 기준으로 배열을 가르는 파티셔닝입니다.
● Pivot 선정 : 배열에서 임의의 한 요소를 피벗으로 선택합니다. (보통 첫 번째, 마지막, 또는 중간값)
● Partitioning : 피벗보다 작은 요소들은 모두 왼쪽으로, 큰 요소들은 모두 오른쪽으로 옮깁니다.
● Recursion (재귀) : 나누어진 왼쪽 배열과 오른쪽 배열에 대해 위 과정을 배열의 크기가 1이 될 때까지 반복합니다.
2. 퀵 정렬의 주요 특징
[1] 압도적인 실제 속도 (캐시 효율성)
배열 내에서 포인터를 스왑하며 내부적으로 데이터 위치를 바꾸는 제자리 정렬(In-place Sort)로 작동하므로, 메모리 캐시 지역성(Cache Locality)이 병합 정렬이나 힙 정렬보다 훨씬 뛰어나 현실 환경에서 가장 빠릅니다.
[2] 불안정 정렬 (Unstable Sort)
값이 동일한 요소들의 상대적인 위치가 파티셔닝 과정에서 뒤바뀔 수 있습니다. 순서 유지가 보장되어야 할 때는 병합 정렬이 더 선호됩니다.
[3] 최악의 경우 O(N²) 주의
배열이 이미 오름차순/내림차순으로 정렬되어 있거나 역순으로 정렬되어 있을 때 피벗을 양 끝으로 잘못 잡으면 파티셔닝이 한쪽으로만 쏠려 최악의 성능을 냅니다.
3. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 최선 / 평균 시간 복잡도 | O(N log N) | 피벗이 배열을 절반씩 균등하게 가를 때 가장 이상적입니다. 분할 깊이(log N) × 병합/비교 수(N). |
| 최악 시간 복잡도 | O(N²) | 피벗이 가장 큰 값이거나 가장 작은 값으로만 선정될 때, 트리 깊이가 N이 되어 O(N²) 성능으로 급감합니다. |
| 공간 복잡도 | O(log N) | 추가적인 배열 메모리는 생성하지 않으나(In-place), 재귀 호출에 따른 콜 스택 메모리가 깊이(log N)만큼 필요합니다. |
💡 실무 지식: 최악의 O(N²)를 피하는 기법
현대의 V8 자바스크립트 엔진이나 C++의 std::sort는 단순 퀵 정렬을 쓰지 않습니다. 배열의 앞, 중간, 뒤의 세 값 중 중간값을 피벗으로 고르는 Median of Three 방법이나, 재귀 깊이가 깊어지면 힙 정렬로 전환하는 인트로 정렬(Introsort) 방식을 결합하여 최악의 경우에도 항상 O(N log N)을 보장하도록 안전하게 최적화되어 있습니다.
// JavaScript 구현
function quickSort(arr, left = 0, right = arr.length - 1) {
if (left >= right) return;
// 파티셔닝 수행 후 피벗의 최종 위치를 받음
const pivotIndex = partition(arr, left, right);
// 피벗을 기준으로 좌/우 재귀 정렬
quickSort(arr, left, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, right);
return arr;
}
function partition(arr, left, right) {
const pivot = arr[right]; // 가장 오른쪽 요소를 피벗으로 선택
let i = left - 1;
for (let j = left; j < right; j++) {
if (arr[j] < pivot) {
i++;
// arr[i]와 arr[j] 교환
[arr[i], arr[j]] = [arr[j], arr[i]];
}
}
// 마지막으로 피벗을 제자리에 둠
[arr[i + 1], arr[right]] = [arr[right], arr[i + 1]];
return i + 1;
}
const arr = [5, 3, 8, 4, 9, 1, 6];
console.log("초기 배열:", arr);
quickSort(arr);
console.log("정렬 결과:", arr);깊이 우선 탐색 (DFS, Depth-First Search)
깊이 우선 탐색 (DFS)
깊이 우선 탐색(DFS, Depth-First Search)은 그래프나 트리의 순회 방법 중 하나로, 한 경로를 선택해 갈 수 있을 때까지 최대한 깊게 파고들어 탐색한 후 더 이상 갈 곳이 없으면 이전 갈림길로 돌아와(Backtracking) 다른 경로를 마저 탐색하는 알고리즘입니다. 미로 찾기를 할 때 한쪽 벽만 계속 짚고 가는 방식과 유사합니다.
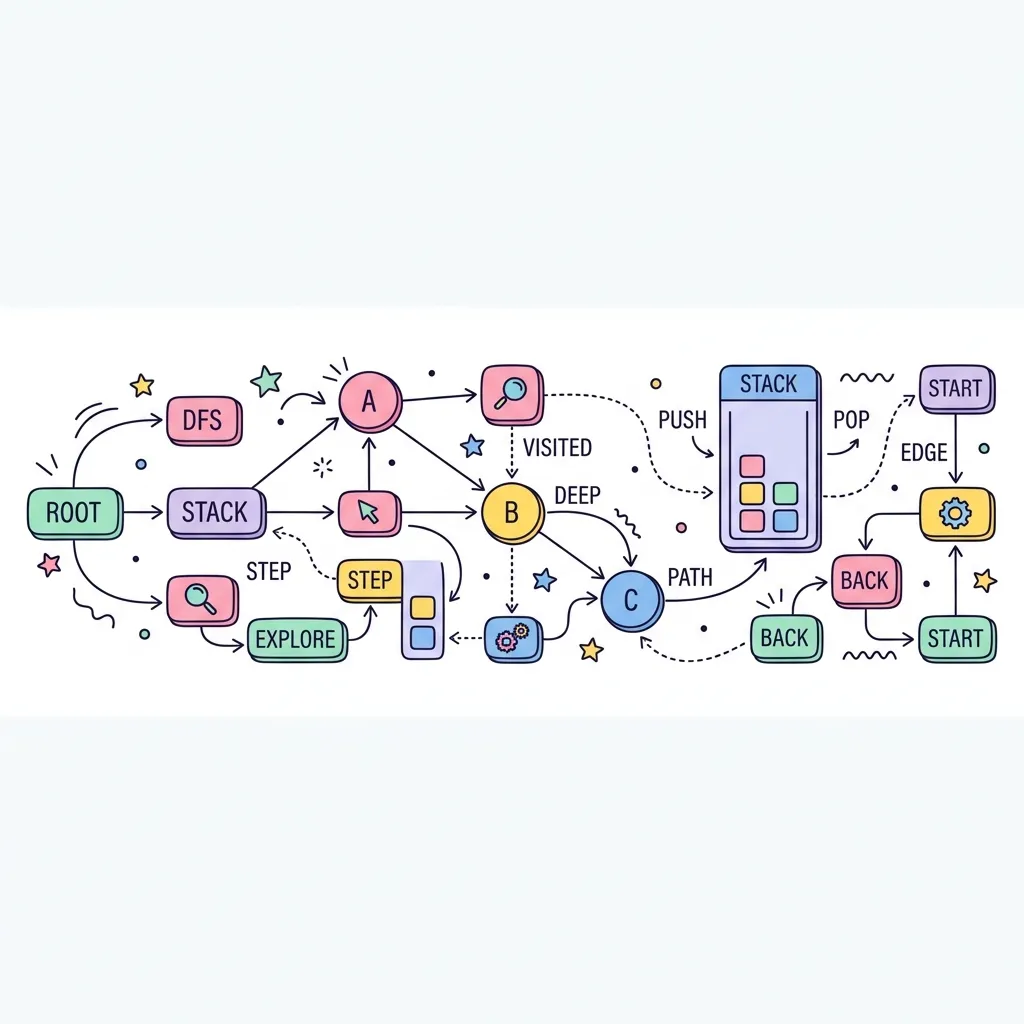
1. DFS의 작동 원리와 특징
DFS는 구현 방식이 간단하며 트리 순회나 완전 탐색 문제에 자주 활용됩니다. 주로 재귀 호출(Recursion)이나 스택(Stack) 자료구조를 사용하여 구현합니다.
● 백트래킹(Backtracking) : 더 이상 방문할 노드가 없으면 직전에 방문했던 노드로 돌아갑니다.
● 방문 처리 필수 : 그래프에는 사이클(순환)이 존재할 수 있으므로 무한 루프에 빠지지 않기 위해 반드시 방문 여부(Visited)를 기록해야 합니다.
● 경로 기억 장점 : 특정 노드까지의 모든 경로 특징을 저장해야 할 때(예: 경로 상의 특정 제약 조건, 문자열 생성 등) BFS보다 유리합니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 시간 복잡도 (인접 리스트) | O(V + E) | V는 정점(Vertex), E는 간선(Edge)의 수입니다. 모든 정점을 한 번씩 방문하고 모든 간선을 탐색하므로 O(V + E)가 됩니다. |
| 시간 복잡도 (인접 행렬) | O(V²) | 간선의 유무를 확인하기 위해 매번 정점 수(V)만큼 반복문을 돌아야 하므로 정점이 많을 때는 리스트보다 불리합니다. |
| 공간 복잡도 | O(V) | 재귀 호출의 콜 스택 크기나 방문 배열 크기가 그래프 깊이에 비례하므로 최대 정점 수인 O(V)의 공간이 필요합니다. |
💡 실무 지식: DFS vs BFS 어느 것을 선택할까?
단순히 '최단 거리'를 구해야 한다면 BFS가 절대적으로 유리합니다. 하지만 각 경로가 가지고 있는 고유한 특성(예: 제약 조건, 방문 노드 경로 저장)을 챙겨가며 끝까지 탐색해야 하거나 백트래킹을 써서 경우의 수를 효율적으로 끊어내야 할 때는 메모리를 적게 먹는 DFS를 선택하는 것이 실무 코딩 테스트나 엔진 로직의 정석입니다.
// JavaScript 구현
const graph = {
1: [2, 3],
2: [4, 5],
3: [6, 7],
4: [],
5: [],
6: [],
7: []
};
function dfs(graph, startNode) {
const visited = new Set();
const result = [];
function explore(node) {
if (visited.has(node)) return;
// 방문 처리
visited.add(node);
result.push(node);
// 인접 노드 깊이 우선 탐색 (재귀)
for (const neighbor of graph[node]) {
explore(neighbor);
}
}
explore(startNode);
return result;
}
console.log("DFS 탐색 결과:", dfs(graph, 1).join(" -> "));
// 출력 결과: 1 -> 2 -> 4 -> 5 -> 3 -> 6 -> 7너비 우선 탐색 (BFS, Breadth-First Search)
너비 우선 탐색 (BFS)
너비 우선 탐색(BFS, Breadth-First Search)은 시작 노드에서 가까운 노드부터 먼저 방문하고 점진적으로 깊이를 넓혀가며(Level-by-Level) 탐색하는 알고리즘입니다. 물가에 돌을 던졌을 때 퍼져나가는 동심원의 물결과 같은 형태로 동작하며, 주로 최단 경로(Shortest Path)를 찾을 때 가장 완벽한 해답을 제공합니다.
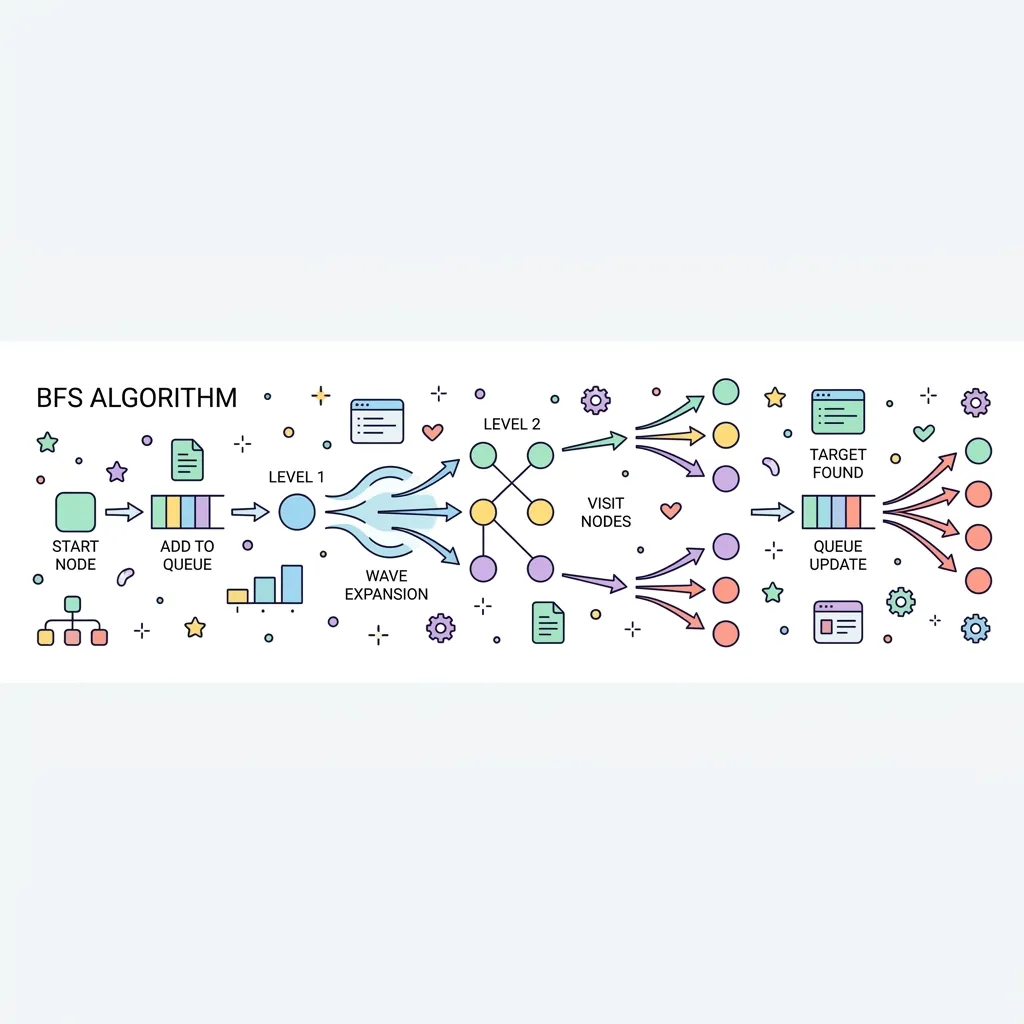
1. BFS의 작동 원리와 특징
BFS는 보통 먼저 들어온 데이터가 먼저 나가는 큐(Queue) 자료구조를 사용하여 구현합니다.
● 최단 경로 보장 : 한 단계(Level)씩 모든 가능성을 탐색하므로, 목표 노드를 발견하는 순간 그 경로가 최단 경로임을 100% 보장합니다.
● 큐(Queue) 활용 : 현재 노드에서 방문할 수 있는 인접 노드를 모두 큐에 밀어 넣고(Push), 순차적으로 꺼내며(Pop) 탐색합니다.
● 메모리 소모량 : 분기가 매우 많은 거대한 그래프의 경우 큐에 엄청난 수의 노드가 쌓이게 되어 DFS보다 메모리 사용량이 치명적으로 높아질 수 있습니다.
2. 시간 및 공간 복잡도 분석
| 평가 기준 | 복잡도 | 심층 설명 |
|---|---|---|
| 시간 복잡도 (인접 리스트) | O(V + E) | V는 정점(Vertex), E는 간선(Edge)의 수입니다. DFS와 마찬가지로 모든 정점을 한 번씩 방문하고 간선을 스캔하므로 O(V + E)가 소요됩니다. |
| 시간 복잡도 (인접 행렬) | O(V²) | 그래프의 연결 형태를 확인하기 위해 V x V 행렬 전체를 순회해야 하므로 정점의 수가 매우 많고 간선이 적은 희소 그래프에서는 비효율적입니다. |
| 공간 복잡도 | O(V) | 최악의 경우(방사형 트리 등) 가장 넓은 레벨에 있는 모든 노드가 큐(Queue)에 한꺼번에 저장되므로, 메모리를 대량으로 차지할 수 있습니다. |
💡 실무 지식: 큐(Queue) 연산의 함정
자바스크립트 등 배열(Array)만 제공되는 언어에서 BFS를 구현할 때 queue.shift() (앞에서 빼기)를 사용하면 O(N) 시간 복잡도가 발생하여 전체 알고리즘 효율이 박살날 수 있습니다. 실무나 알고리즘 테스트에서는 반드시 앞뒤 삽입/삭제가 O(1)로 이뤄지는 연결 리스트 기반의 큐나 투 포인터(Two Pointer) 방식을 직접 구현하여 사용해야 합니다!
// JavaScript 구현
const graph = {
1: [2, 3],
2: [4, 5],
3: [6, 7],
4: [],
5: [],
6: [],
7: []
};
function bfs(graph, startNode) {
const visited = new Set([startNode]);
const queue = [startNode];
const result = [];
// shift()의 O(N) 방지를 위한 투 포인터 방식 권장
let head = 0;
while (head < queue.length) {
const node = queue[head++]; // O(1) 추출
result.push(node);
// 인접 노드들을 레벨 단위로 모두 큐에 삽입
for (const neighbor of graph[node]) {
if (!visited.has(neighbor)) {
visited.add(neighbor);
queue.push(neighbor);
}
}
}
return result;
}
console.log("BFS 탐색 결과:", bfs(graph, 1).join(" -> "));
// 출력 결과: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7동적 계획법 (Dynamic Programming - 피보나치)
동적 계획법 (Dynamic Programming)
동적 계획법(DP)은 복잡하고 거대한 문제를 아주 작은 단위의 하위 문제(Sub-problem)들로 쪼개어 풀되, 동일한 연산이 반복될 때 그 결과값을 저장(캐싱)하여 재사용함으로써 중복 연산을 극적으로 줄이는 기법입니다. "기억하며 풀기"라고도 부릅니다.
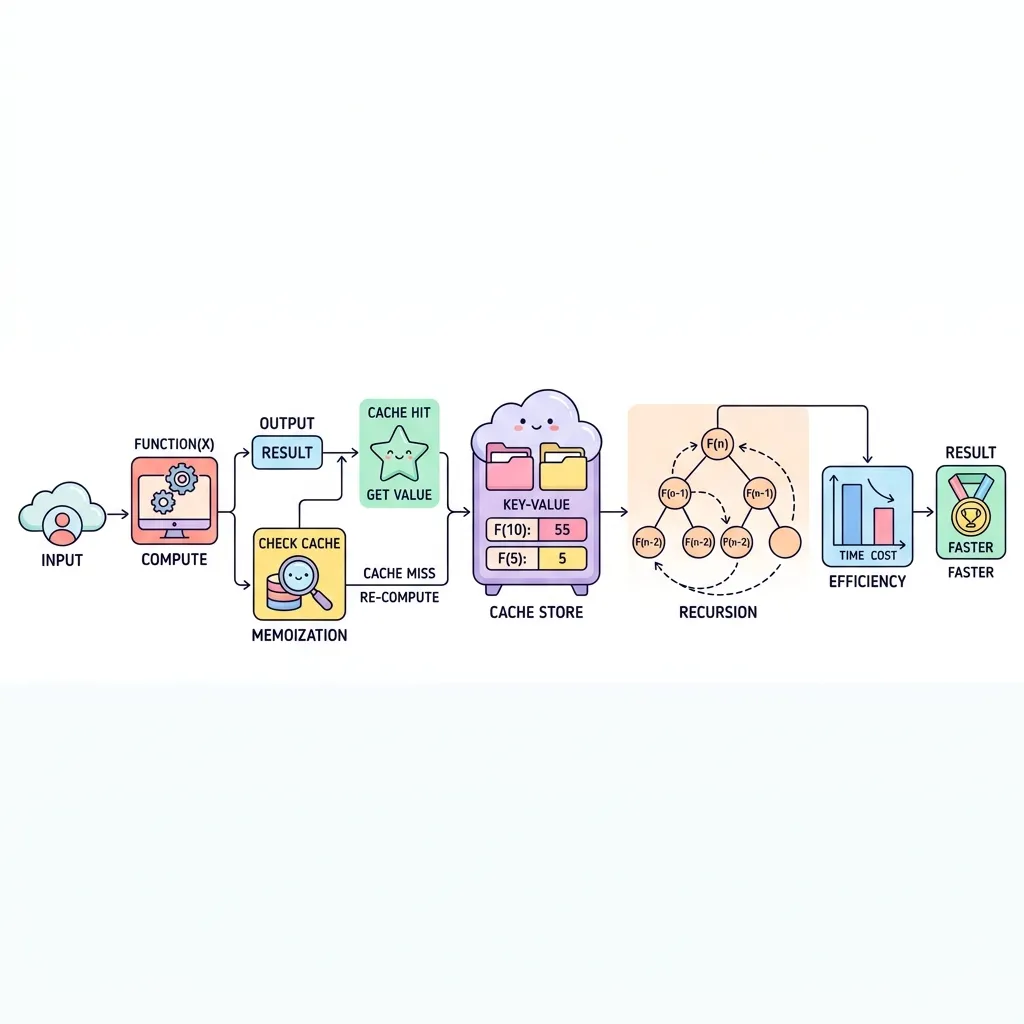
1. 동적 계획법의 핵심 원리: 메모이제이션
피보나치 수열을 단순 재귀 함수로 구현하면 F(3)이나 F(2) 같은 똑같은 함수를 수백, 수천 번 반복 호출하게 됩니다. 이를 해결하는 마법이 바로 메모이제이션입니다.
● 중복 연산 방지 : 한 번 뼈빠지게 계산해 낸 결과는 memo 배열이나 딕셔너리에 몰래 적어(저장해) 둡니다.
● Cache Hit! : 이후 또다시 똑같은 함수 호출이 들어오면, 로직을 실행하지 않고 노트(캐시)에 적어둔 답만 O(1)의 속도로 쓱 꺼내서 반환합니다.
● 시간 복잡도의 마법 : 우주가 멸망할 때까지 걸린다는 최악의 O(2^N) 지수 시간이, DP를 적용하는 순간 선형 시간인 O(N)으로 단축되는 기적을 보여줍니다.
2. Top-Down(메모이제이션) vs Bottom-Up(타불레이션)
| 방식 | 구현 방법 | 장점 및 특징 |
|---|---|---|
| Top-Down (하향식) |
재귀함수 + Cache(Memo) | 큰 문제부터 시작해 작은 문제로 파고듭니다. 수학적 점화식을 직관적으로 코드로 옮기기 쉬우나, 콜 스택(Call Stack) 깊이 초과 에러가 발생할 위험이 있습니다. |
| Bottom-Up (상향식) |
반복문(for) + DP Table(Array) | 작은 문제부터 차근차근 배열을 채워 올라갑니다. 콜 스택 오버플로우 걱정이 없고 성능 튜닝에 유리해 실무 및 코딩테스트에서 가장 권장되는 방식입니다. |
// JavaScript 구현 (Top-Down: Memoization)
// 실무에서는 전역 객체보다 클로저나 클래스 인스턴스 멤버를 사용하는 것이 안전합니다.
function getFibonacciWithMemo() {
const memo = {}; // 계산 결과를 저장할 캐시 객체
return function fibo(n) {
if (n <= 1) return n;
// 1. 캐시 히트(Cache Hit) 확인
if (memo[n] !== undefined) {
console.log(`F(${n}) 캐시 히트!`);
return memo[n];
}
// 2. 미연산 값이라면 점화식을 통해 계산 후 캐시에 저장
console.log(`F(${n}) 계산 중...`);
memo[n] = fibo(n - 1) + fibo(n - 2);
return memo[n];
};
}
const dpFibo = getFibonacciWithMemo();
console.log("F(5) 결과:", dpFibo(5));다익스트라 최단 경로 (Dijkstra Algorithm)
다익스트라 최단 경로 (Dijkstra)
다익스트라 알고리즘(Dijkstra)은 다이나믹 프로그래밍(DP)과 그리디(Greedy) 알고리즘 기법을 결합하여 특정 출발 노드에서 다른 모든 노드까지의 '가장 짧은 경로(최소 비용)'를 완벽하게 찾아내는 알고리즘입니다. 오늘날 GPS 내비게이션 길 찾기 기능의 근간이 되는 아주 강력하고 대표적인 라우팅 기법입니다.
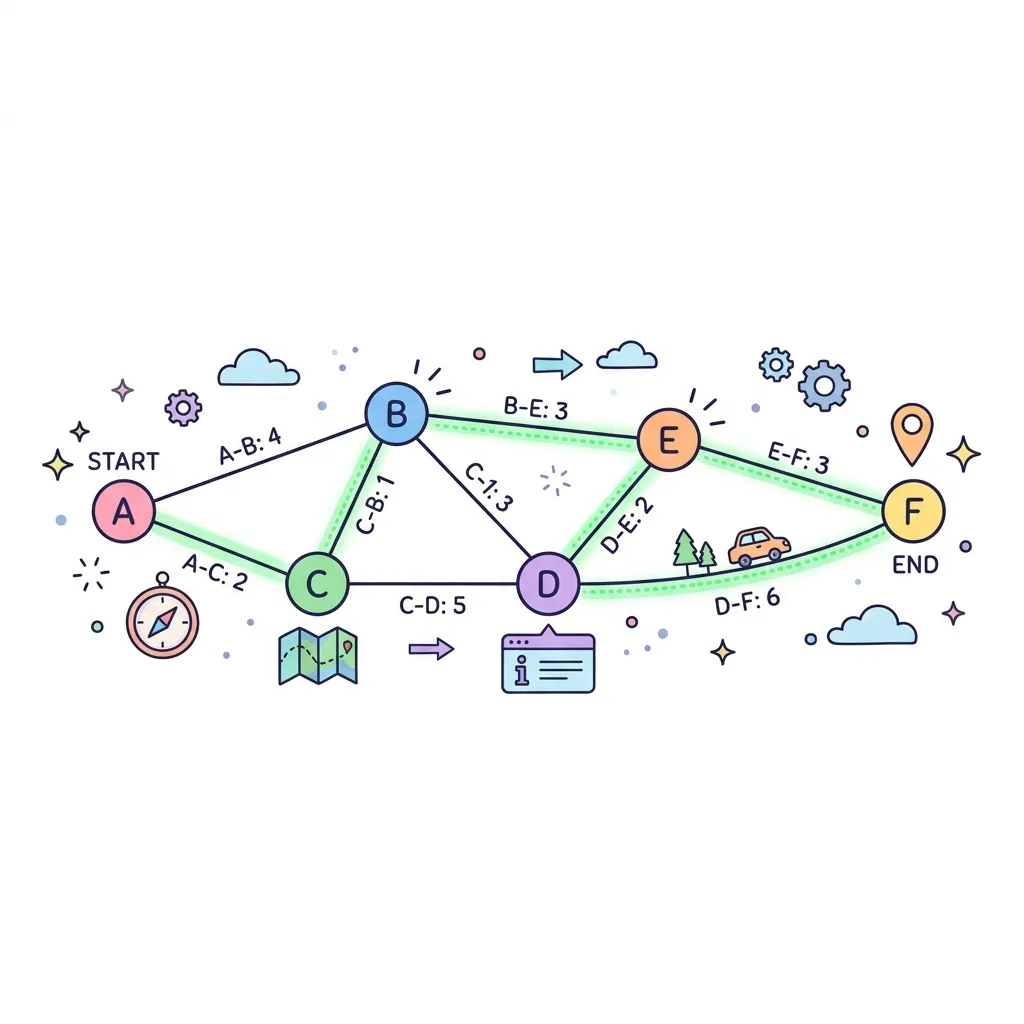
1. 다익스트라의 작동 원리와 특징
다익스트라는 매 순간 '가장 가까운 노드'를 선택하며 거리를 갱신합니다(Relaxation).
● 우선순위 큐(Priority Queue) : 단순히 배열을 돌며 가장 짧은 거리를 찾으면 O(V²)이 걸리지만, 우선순위 큐(최소 힙)를 사용하면 O(E log V)로 속도가 비약적으로 상승합니다.
● 거리 갱신 (Relaxation) : 현재 노드를 거쳐서 특정 노드로 가는 비용이, 기존에 알고 있던 비용보다 저렴하다면 최소 비용을 갱신합니다.
● 한계점 (음수 간선) : 음수 가중치(비용이 마이너스)를 가진 간선이 존재한다면 알고리즘이 고장납니다. 이 경우 벨만-포드(Bellman-Ford) 알고리즘을 사용해야 합니다.
2. 시간 및 공간 복잡도 분석
| 구현 방식 | 시간 복잡도 | 심층 설명 |
|---|---|---|
| 순차 탐색 (선형 탐색) | O(V²) | 매번 방문하지 않은 노드 중에서 '가장 최단 거리가 짧은 노드'를 찾기 위해 모든 노드를 스캔합니다. 노드(V)가 10,000개 이하라면 쓸만하지만 그 이상이면 병목이 옵니다. |
| 우선순위 큐 (최소 힙) | O(E log V) | 최단 거리를 가진 노드를 즉각적으로 뽑아내는 최소 힙(Min-Heap)을 사용하면, 노드가 100만 개 단위인 거대한 그래프 처리도 순식간에 끝냅니다. |
💡 실무 지식: 자바스크립트에서의 다익스트라 구현
Java(PriorityQueue)나 Python(heapq), C++(std::priority_queue)는 우선순위 큐를 표준 라이브러리로 강력하게 지원하지만, 안타깝게도 JavaScript/TypeScript는 내장된 우선순위 큐(Priority Queue) 자료구조가 없습니다. 실무 알고리즘 테스트 시에는 직접 Min-Heap 클래스를 구현해서 풀거나, 데이터가 크지 않다면 단순 배열 선형 탐색 O(V²)으로 빠르게 제출하는 것이 현실적인 전략입니다.
// JavaScript 구현 (가장 단순한 O(V^2) 방식 - 코딩테스트용)
const graph = {
'A': { 'B': 2, 'C': 5 },
'B': { 'C': 1, 'D': 3 },
'C': { 'D': 6 },
'D': {}
};
function dijkstra(graph, start) {
const distances = {};
const visited = new Set();
// 초기화
for (let node in graph) {
distances[node] = Infinity;
}
distances[start] = 0;
while (true) {
let currNode = null;
let shortestDist = Infinity;
// 방문하지 않은 노드 중 가장 거리가 짧은 노드 탐색 (내장 PQ가 없어서 선형 탐색)
for (let node in distances) {
if (!visited.has(node) && distances[node] < shortestDist) {
shortestDist = distances[node];
currNode = node;
}
}
if (currNode === null) break;
visited.add(currNode);
// 인접 노드 거리 갱신 (Relaxation)
for (let neighbor in graph[currNode]) {
let cost = distances[currNode] + graph[currNode][neighbor];
if (cost < distances[neighbor]) {
distances[neighbor] = cost; // 최단 거리 갱신
}
}
}
return distances;
}
console.log("시작점 A 기준 최단 거리:", dijkstra(graph, 'A'));
// 출력: { A: 0, B: 2, C: 3, D: 5 }